背景
起因是钉钉群内发现大量告警
查看集群状态,发现node状态在ready和notready之间反复横跳,有问题的node都是某地区IDC机房的节点,集群跟该地区IDC节点组网使用基于WireGuard协议的应用,节点间通信依赖公网出口。
问题定位
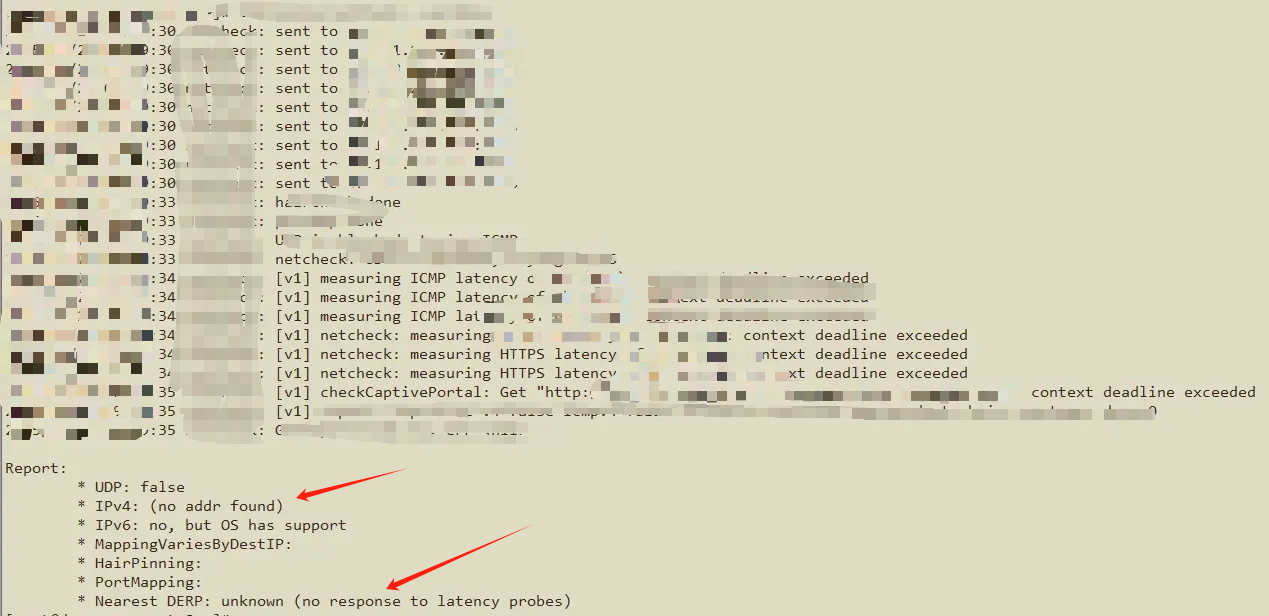
agent组网节点检查
检查组网节点是否工作正常
发现是agent节点出现无法连接中继节点或者直连master节点,所以有可能是网络问题
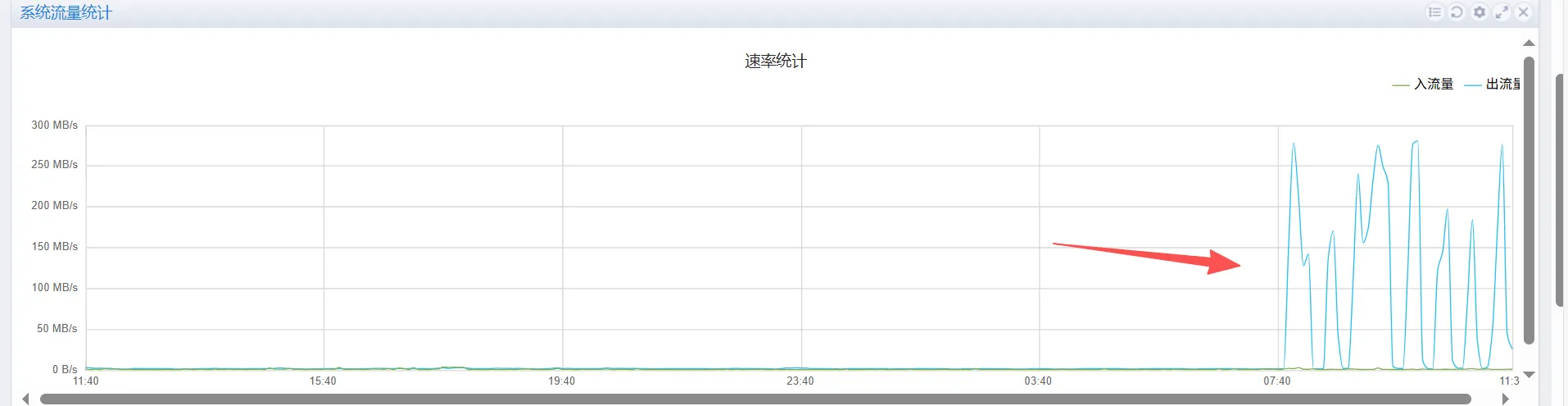
机房公网流量检查
查看机房公网流量出口,发现公网的出流量把带宽都占满了,可以确定是有人把公网出流量占满了,导致集群组网出现问题,从而出现节点notready的情况
排查
集群内的公网流量分为:
- 内部流量:各个pod、node之间相关访问的流量(因为有组网,所以这些内部流量也是走公网出口)
- 外部流量:集群中的工作负载通过网关访问公网
内部流量排查
集群中内部组网使用了agent节点,所以该机房中的内部流量都会走该agent出去,查看其流量趋势
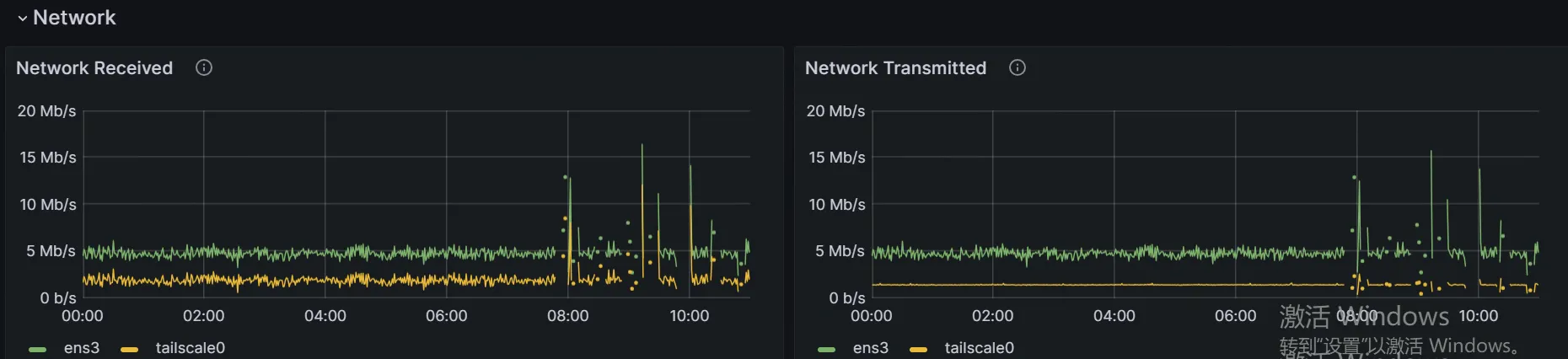
发现流量数据还算正常,排除集群内大流量的问题
外部流量排查
集群使用kube-ovn CNI,外部公网流量分为集中式网关和分布式网关两种方式。
- 集中式网关用的是 vpc-nat-gateway + multus-cni ,它会把节点上面的网卡加入到对应pod上面,所以可以通过查看对应节点的网卡流量情况得出该网关的流量情况。
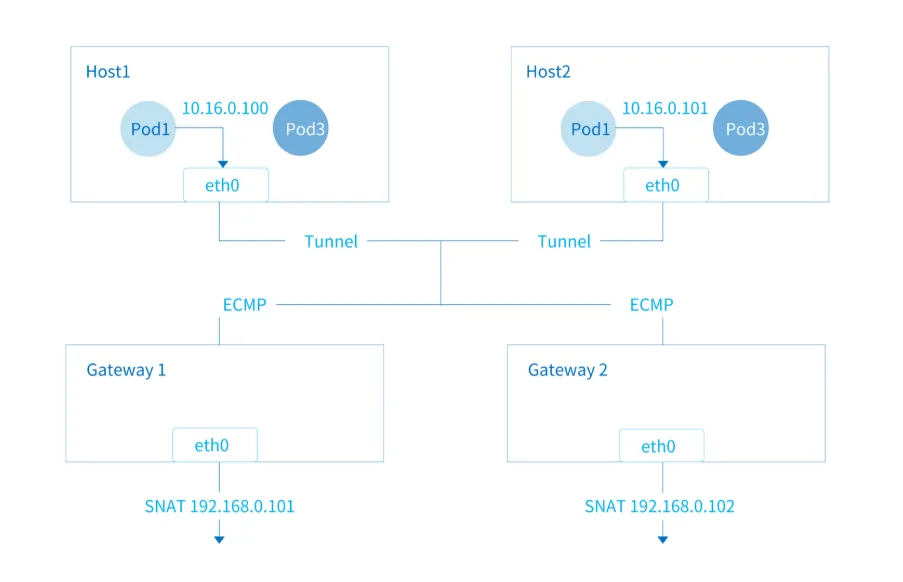
- 分布式网关是pod访问公网时,流量会经过pod所在节点的网卡,走节点自身的网络。
因为集群里面的节点都安装了node-exporter,所以可以使用pmql来定位哪个节点的网卡出流量最多
# 3小时内,平均发送数据(MB)top5的网卡信息
topk(5, sum by (instance,device) (rate(node_network_transmit_bytes_total{device!~"lo|veth.*|docker.*|br.*"}[3h]))) / 1024 / 1024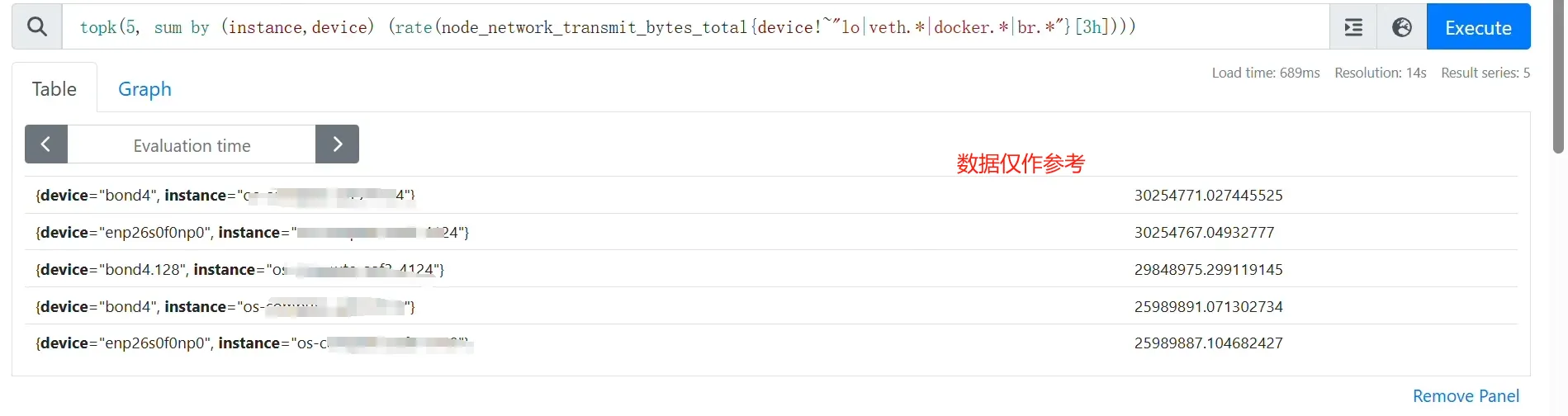
结果发现有一张网卡的流量十分高,定位到是一个集中式网关的节点,上面的网卡被用来做网关的公网出口网卡了,所以可以确定大流量的应用就在这个网关后面。
在集群中使用集中式网关的都会给它分配一个EIP资源,同时集群里面也有对应的exporter来收集EIP的流量使用情况,所以可以继续使用对应的pmql来定位对应的EIP资源。
# 内部查看eip流量的pmql,仅供参考
topk(5, sum by (eipName) (rate(xxx_eip_network_traffic_egress_bytes{xxx}[3h]))) / 1024 / 1024在成功定位到有问题的EIP后,后台马上找到了对应的资源,是一台裸金属。
这台裸金属在1个月前因初始配置不当导致未授权访问,并被修改了密码,在修改密码后就可以登录回去了。但是因为上面有一些虚拟机应用在跑,所以没有选择重装系统,而是重装了部分核心软件,并检查和清除相关入侵痕迹。所以可以确定是裸金属被黑了导致出流量激增,不是因为相关业务。
处理
这里处理分为两步:
- 对应的同学备份虚拟机和系统上面的重要数据,确保系统可以重装
- 对裸金属进行临时处理,并且看一下是否可以找到对应的问题
裸金属处理
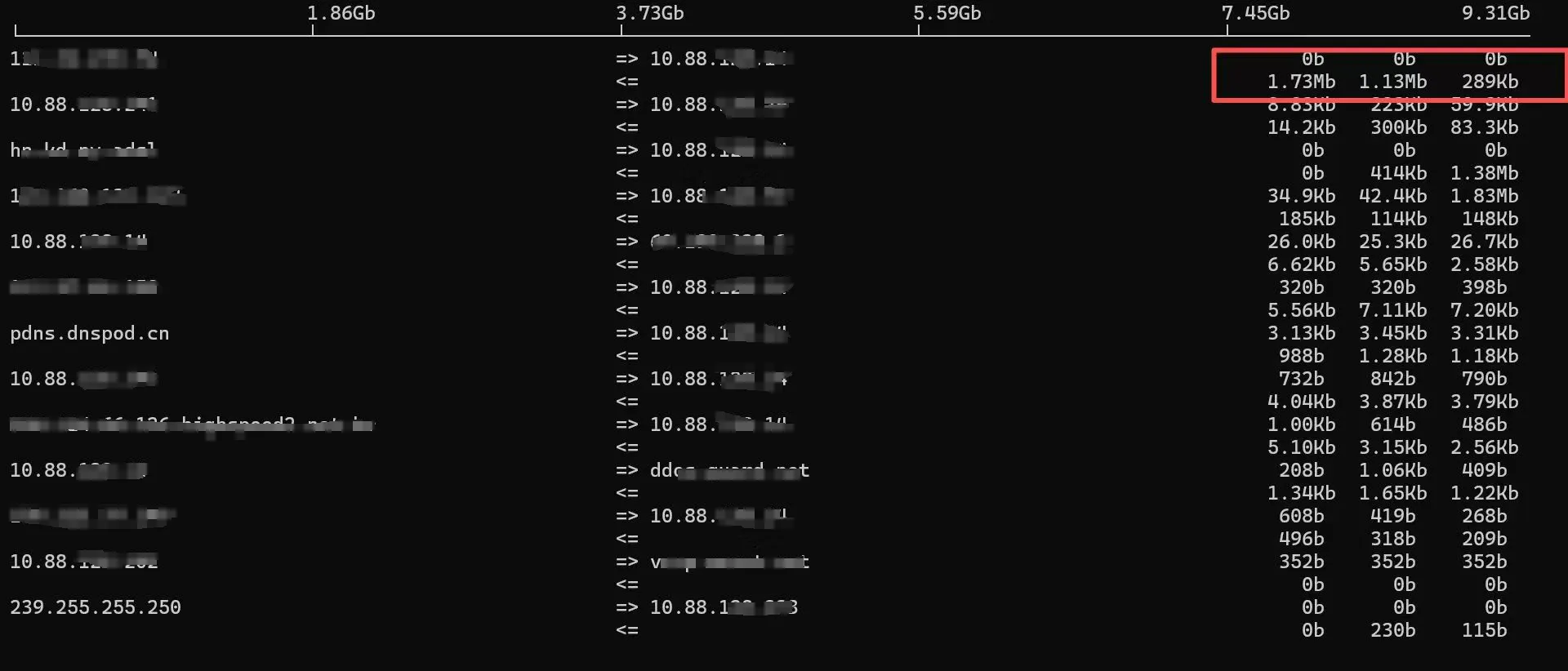
流量查看
通过iftop查看实时流量,发现随机向多个IP发送大流量数据
使用tcpdump进行抓包查看相关数据,发现流量会访问目标ip的80或443端口,并且会一直发送SYN包
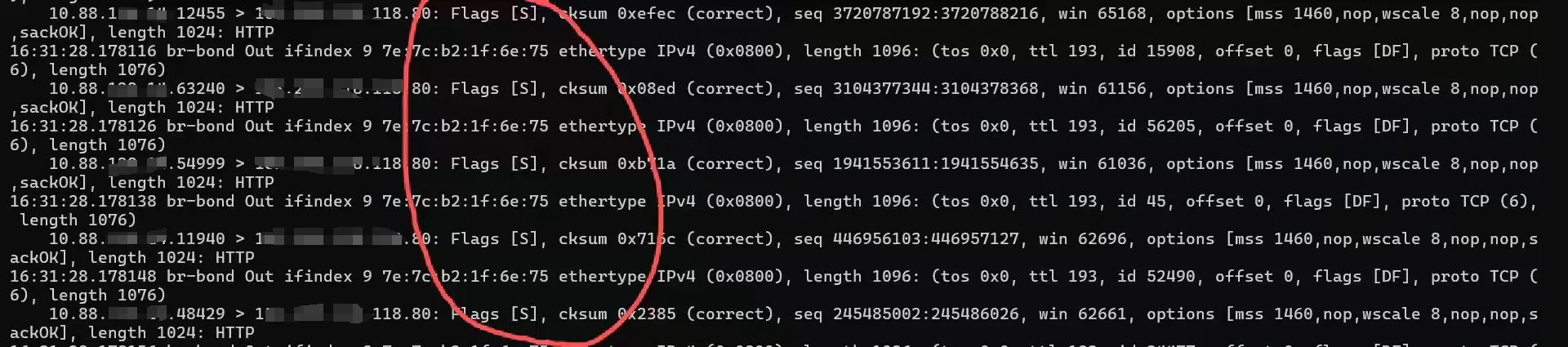
综上所述,这台服务器是被人拿来做肉鸡,对公网服务发起SYN洪水攻击
临时处理
为避免进一步影响业务,临时用tc给系统限速,确保不要再发送大流量把系统公网带宽占满。要求:业务ip流量不限制(ssh登录ip、虚拟机的业务流量),只限制异常流量(所有ip的80、443端口出流量)。
# 清空对应网卡旧规则
# tc qdisc del dev enp1s0 root
# 添加qdisc,并且默认归类为 1:20 的规则(没有匹配到规则的流量走 1:20 )
# tc qdisc add dev enp1s0 root handle 1: htb default 20
# 添加class规则
# tc class add dev enp1s0 parent 1: classid 1:1 htb rate 20Mbit ceil 20Mbit burst 15k
# 异常流量限速规则
# tc class add dev enp1s0 parent 1:1 classid 1:10 htb rate 1Mbit ceil 1Mbit burst 1k
# 其它流量规则
# tc class add dev enp1s0 parent 1:1 classid 1:20 htb rate 20Mbit ceil 20Mbit burst 15k
# 为了避免一个会话永占带宽,添加随即公平队列sfq
# tc qdisc add dev enp1s0 parent 1:10 handle 10: sfq perturb 10
# tc qdisc add dev enp1s0 parent 1:20 handle 20: sfq perturb 10
# 添加filter来应用class规则,这里是目标端口为80、443的都到 1:10的class 中
# tc filter add dev enp1s0 protocol ip parent 1:0 prio 3 u32 match ip dport 443 0xffff flowid 1:10
# tc filter add dev enp1s0 protocol ip parent 1:0 prio 2 u32 match ip dport 80 0xffff flowid 1:10
# 规则检验
# tc qdisc show dev enp1s0
# tc class show dev enp1s0
# tc filter show dev enp1s0
# 数据统计 查看有多少流量命中那些规则
# tc -s class show dev enp1s0
# tc -s filter show dev enp1s0 限速后,公网流量恢复正常,集群节点状态恢复。
排查
直接说结论,还没有排查出来问题系统就被重装了,所以怀疑是有问题的进程被替换成正常的进程程序了。😥
这里说一下排查思路和过程:
- 重新安装基础命令工具(ps、ss、lsof等)
- 使用 iftop 持续监控流量
- 使用 ss、ps、lsof 定位可疑进程:
- 未发现可疑进程与攻击IP的连接
- 发现几个异常公网ip的VNC-console连接,禁止相关IP访问后重启libvirt服务,问题仍存在
- 检查系统日志、登录日志、操作日志、安全日志及内核日志
- 检查iptables配置,确认无异常丢弃ACK/FIN包规则
- 检查定时任务、启动脚本、可疑用户及登录信息
- 检查虚拟机内部流量,确认正常
- 使用Rootkit工具进行全面检查
值得注意的是,上述排查后发现,自上次修改密码后,系统无任何可疑IP登录记录,怀疑攻击者在初次入侵时植入了持久化后门或恶意程序。
最后在其他同学备份好相关文件后,对系统进行了重装。
总结
在经历了上述事件后,还是要加强以下两点:
- 系统暴露在公网环境下,最好是不要用弱密码(用密钥或者强密码)并且要开启防火墙,限制可以登录的ip白名单。
- 要精细化监控告警,像上述的问题都是通过PMQL来定位的,这样完全可以编写对应的告警规则,在出现相关问题的时候,第一时间可以定位到对应的资源,加快故障恢复速度。