背景
近日,团队发现阿里云上某个项目的Prometheus监控实例成本异常高昂,月均费用达到2-3千元,而其他类似规模的项目仅需几百元。我对此进行了成本优化。
架构
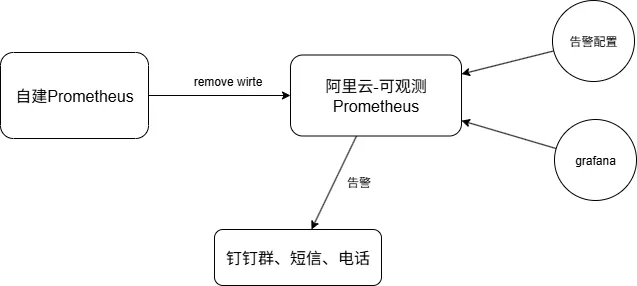
在我们项目的集群中是有自建的Prometheus实例的,同时采用了混合监控方案:
- 集群内部署了自建Prometheus实例,负责基础监控数据的采集和存储
- 通过Prometheus的remote_write功能,将监控数据同步至阿里云ARMS Prometheus
- 告警功能完全依赖阿里云Prometheus的高级规则配置实现
这种架构设计初衷是为了利用阿里云Prometheus更强大的告警管理能力,但同时也带来了额外的成本。
问题诊断
首先,我登录阿里云控制台查看该Prometheus实例的指标数据,发现基础指标和自定义指标数量均异常高。然而,当我检查集群内自建Prometheus的数据存储量时,仅显示400多GB,与阿里云上显示的规模明显不符。
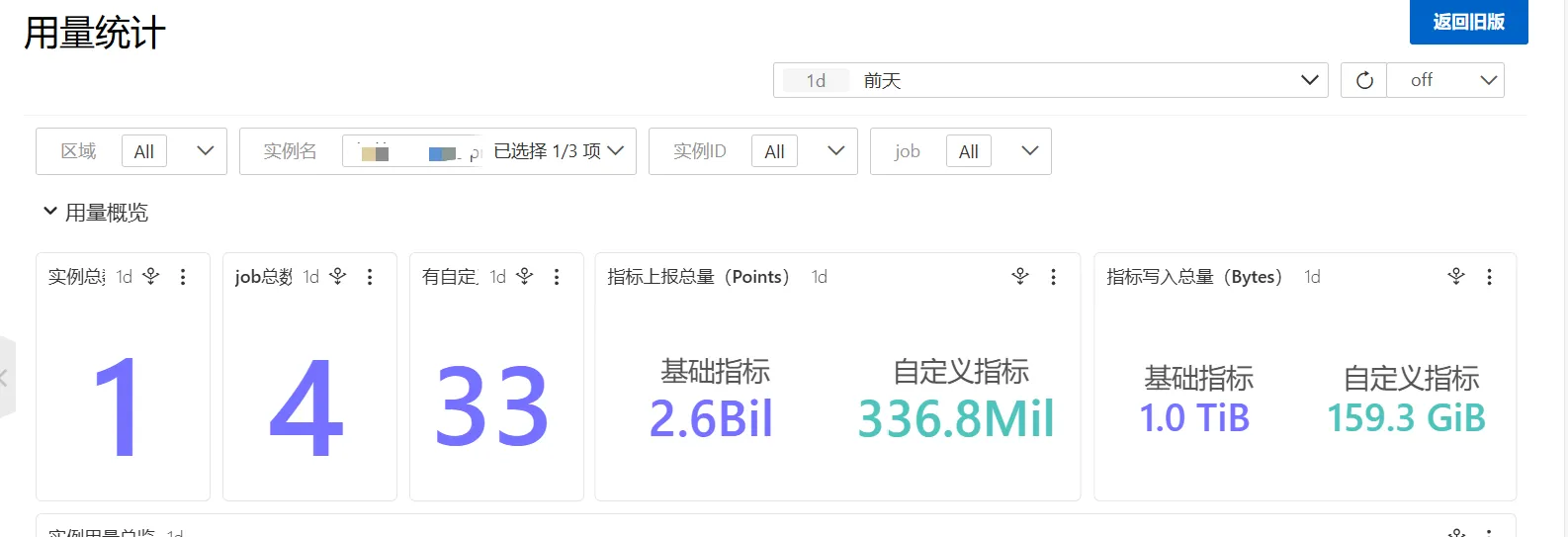
因此直接给阿里云提上工单询问为什么本地看的Prometheus存储数据和阿里云上面看到的不一致。
在客服询问后得知,阿里云上面的指标数据是未经过压缩的,而Prometheus本地查看的数据是经过了压缩的,所以存储占用看起来会少很多。
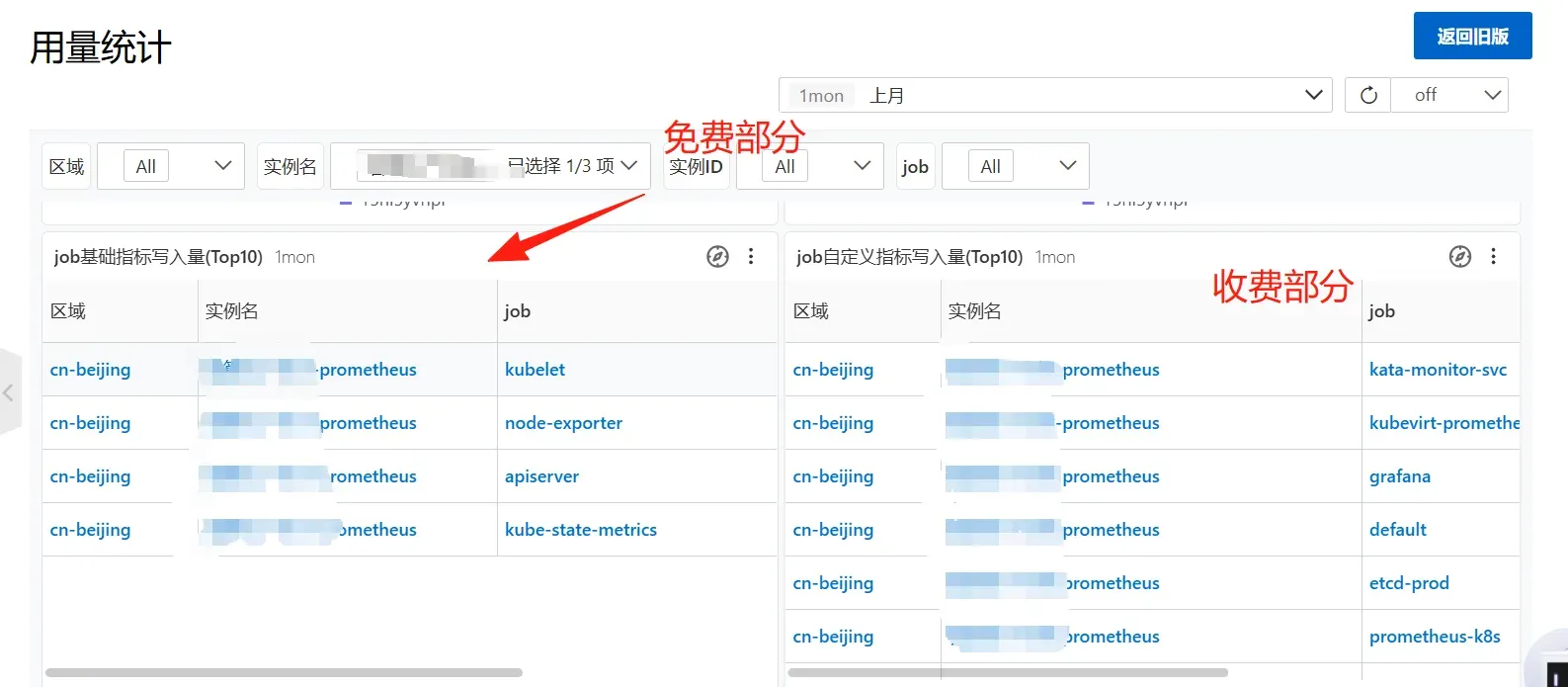
看来只能做相关远程写的指标优化,首先要确定阿里云Prometheus的收费标准
在查询文档和询问客服后得知得知阿里云Prometheus的收费是分两种,计费方式为里面任意一种。
- 按写入量收费,分为基础指标(免费)和自定义指标(收费)
- 按上报量收费,也是分为基础指标(免费)和自定义指标(收费)
Prometheus 实例的计费方式、计费项、计费单价和开通方式_应用实时监控服务(ARMS)-阿里云帮助中心
并且远程写里面也是可以区分基础指标(免费)和自定义指标(收费)
特别关键的是,通过remote_write同步的数据也可以区分基础指标和自定义指标。这意味着我们可以通过配置relabel规则,精确控制哪些指标需要同步到阿里云,从而大幅降低费用。
优化方案
基于以上分析,我制定了以下优化策略:
- 保留所有免费的基础指标:确保Kubernetes核心组件监控不受影响
- 精简自定义指标:仅保留需要告警的关键业务指标
- 停用阿里云Grafana:改用集群内自建的Grafana实例,避免额外费用
配置
集群中使用的Prometheus安装方的是 prometheus-operator
所以可以按照文档里面的方式对remove wirte配置进行修改 相关文档
这里是直接修改集群中Prometheus对象
在spec.remoteWrite.writeRelabelConfigs 中进行配置
这里我配置是以job为最小单位,虽然告警用的是特定的指标数据,但是在查看相关自定义job的数据后,发现它们的占用并不高,同时因为每次修改完后remoteWrite的相关配置后,都要重启Prometheus,所以也是为了避免后续因调整告警规则而不断重启Prometheus,所以考虑使用了job的范围来做relabel的配置
remoteWrite
writeRelabelConfigs:
- sourceLabels: [job]
regex: '^(apiserver|node-exporter|kube-state-metrics|kubelet|metallb-metrics|kube-dns|xxx-.*|ceph-.*|.*etcd.*)$'
action: keep配置好后,重启对应的statefulset
Kubectl rollout restart statefulsets.apps prometheus-k8s -n monitoring验证
在配置好后,到指标中心查看up的job
sum(up{}) by (job)同时逐一验证每个告警规则的PromQL表达式,确保所有关键告警仍能正常触发
优化效果
在配置好并过了一天后查看对应数据
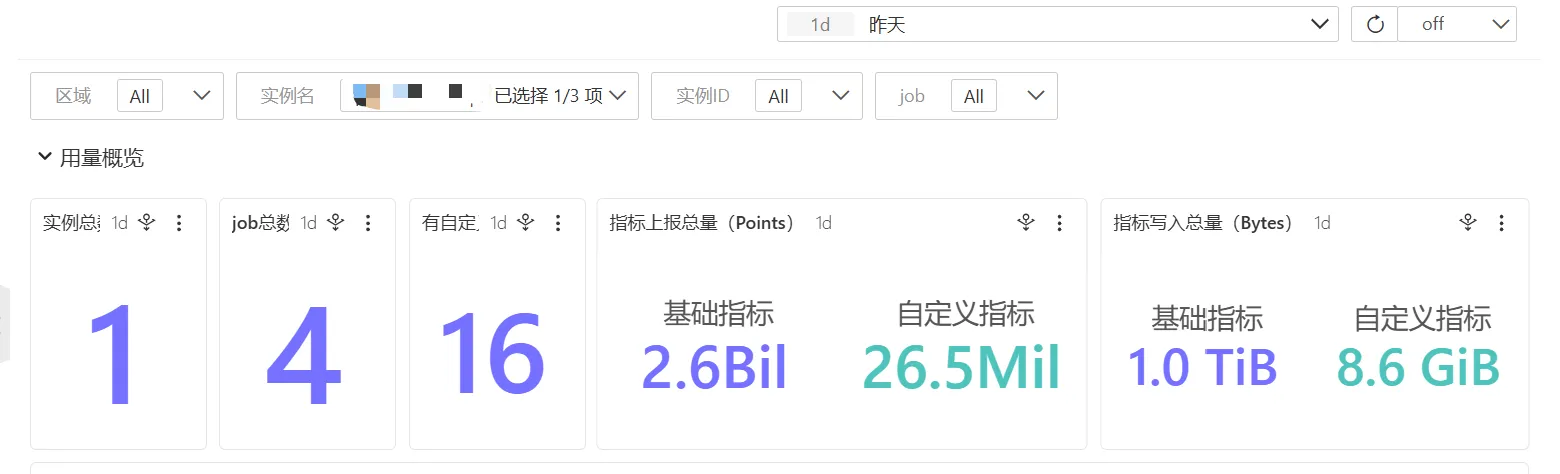
从上面可以看出对应的自定义指标数据有大幅下降,同时在查看成本后,发现对应的Prometheus的成本也是下降了。
原先是每天160G x 0.4(我们的Prometheus是0.4每G) = 64 下降成 9G x 0.4 = 3.6
总结
通过合理配置Prometheus的remote wirte规则,成功将阿里云Prometheus实例的成本降低了90%以上,同时完整保留了告警功能。唯一的变动是将Grafana查看地址切换回集群内部署的实例。
这次优化实践表明,云服务的成本控制不仅需要关注资源规格,更需要深入理解服务的计费模型,通过技术手段精准控制资源消耗。
对于使用阿里云Prometheus的团队,建议定期审查指标摄入情况,避免不必要的费用支出。