本次配置和代码都在github上
使用方法:
git clone https://github.com/kehaha-5/k8s_demo
cd k8s_demo
git fetch --all
git checkout -b tag 1.0
概述
目标
- 部署mysql集群
- 部署redis集群
- 部署一个前后端分离的项目
- 后端gin纯api
- 前端vue3
环境
服务器一共有3台:
- 主服务器(4c,6g) 是集群里面的server节点
- 节点服务器1(2c,4g) 是集群里面的agent节点
- 节点服务器2(2c,2g) 该服务器不仅是集群里面的agent节点,也是项目中的前端服务器
那为什么要专门弄一台低配置的服务器专门运行前端?
前端的资源流量会在web占据比较大的部分,即使上了
cdn在某些时刻也会存在流量回流到服务器的,导致服务器带宽被占满,若后端也是部署在该服务器上面,会因为服务器带宽问题导致api的响应变慢,带来不好的用户体验。同时进行合理的资源分配也可以节约成本
- 一台nfs存储服务器
- 所有服务器都在同一个内网下,可以相互ping通
前期准备
集群搭建
这次利用k3s来进行集群的搭建,k3s是一个轻量级的kubernetes集群,相比较于k8s,k3s的资源占用更少,并且部署更加简单。
在利用k3s部署集群的时候要注意一下几点:
- 默认的k3s集群的储存是使用sqlite3,这个并不适合在高可用的生产环境下使用,所以在正式的生产环境中要使用k3s-高可用外部数据库
- 在存储定义方面
pvc中,k3s是没有Kubernetes这么多卷插件的,需要自己去配置 k3s-卷和存储 - 集群访问的方式,k3s默认使用
k3s kubectl命令行进行集群的访问,如果是另外安装的kubectl,需要配置kubectl的访问方式,另外helm也是如此 k3s-集群访问 - k3s默认是使用了
traefik作为集群的ingress controller,相关配置文件的位置和信息 k3s-Networking Services - 在k3s中如果需要配置镜像源可以参考 k3s-Private Registry Configuration,同时最好启用
Embedded Registry Mirror功能,这个可以使节点通过集群里面的其他节点获取已有的镜像 k3s-Embedded Registry Mirror
额外配置
因为在上述中提到需要一台服务器专门做web资源服务器,所以在部署完集群后,需要把对应服务node打上污点,防止其他pod被调度到该节点上面
root@node-m:~/k8s# kubectl taint nodes node-res type=res:NoSchedule
# 其中NoSchedule的含有如下和其他污点类型:
# NoSchedule :表示k8s将不会将Pod调度到具有该污点的Node上
# PreferNoSchedule :表示k8s将尽量避免将Pod调度到具有该污点的Node上
# NoExecute :表示k8s将不会将Pod调度到具有该污点的Node上,同时会将Node上已经存在的Pod驱逐出去
root@node-m:~/k8s# kubectl describe nodes node-res
Name: node-res
...
Taints: type=res:NoSchedule
Unschedulable: false
...或者使用k3s中的agent配置文件给节点进行污点配置 k3s-agent
同时创建一个prod的namespace,我的所有应用都将会部署到该namespace上面
apiVersion: v1
kind: Namespace
metadata:
name: prod
labels:
name: prod开始部署
kubernetes dashboard
根据文档命令部署 dashboard
# Add kubernetes-dashboard repository
helm repo add kubernetes-dashboard https://kubernetes.github.io/dashboard/
# Deploy a Helm Release named "kubernetes-dashboard" using the kubernetes-dashboard chart
helm upgrade --install kubernetes-dashboard kubernetes-dashboard/kubernetes-dashboard --create-namespace --namespace kubernetes-dashboard部署完后我们还要创建一个用户用于管理k8s Creating sample user
完成上述部署以后,我们就要访问对应的dashboard,然后我是要用ip+端口的访问方式,所以还要创建一个service把流量代理到对应的pod上
cat node-web.yaml
apiVersion: v1
kind: Service
metadata:
name: dashoard-web
namespace: kubernetes-dashboard
labels:
k8s-app: kubernetes-dashboard
spec:
type: NodePort #这里使用NodePort 因为我想要从集群外部访问
selector:
app.kubernetes.io/name: kong
ports:
- protocol: TCP
port: 8000
targetPort: 8443注意这里要代理的是kubernetes-dashboard-kong不是kubernetes-dashboard-web
root@node-m:~/k8s/dashoboard# kubectl get endpoints -n kubernetes-dashboard
NAME ENDPOINTS AGE
dashoard-web 10.42.1.242:8443 12d
...
kubernetes-dashboard-kong-proxy 10.42.1.242:8443 34h
...
#这里可以看到我的dashoard-web已经绑定到kubernetes-dashboard-kong-proxy上了
kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashoard-web NodePort 10.43.234.91 <none> 8000:30756/TCP 12d
...
#查看service信息可以得知 dashoard-web 的外部访问端口为 30756然后ip+30756 即可访问 dashboard 同时还要创建对应用户的token
root@node-m:~/k8s/dashoboard# kubectl create token -n kubernetes-dashboard xxxx
NFS存储挂载
在所有应用部署前,先部署外部存储介质
首先先要安装 csi-driver-nfs 这个是nfs的卷插件,不安装的话是无法使用nfs相关卷功能
root@node-m:~/k8s# cat ./nfs/storageClass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs
provisioner: nfs.csi.k8s.io
parameters:
server: 192.168.1.125
share: /mnt/nfs_share
# csi.storage.k8s.io/provisioner-secret is only needed for providing mountOptions in DeleteVolume
# csi.storage.k8s.io/provisioner-secret-name: "mount-options"
# csi.storage.k8s.io/provisioner-secret-namespace: "default"
reclaimPolicy: Retain #因为要保存redis 和 mysql的数据 所以使用Retain 当pvc或pv被删除以后仍然可以保留数据
volumeBindingMode: Immediate
mountOptions:
- nfsvers=4这里使用的是 Dynamic Volume Provisioning 这样就不需要每个pvc都声名一个pv了
MySQL集群
这里要部署的是一个1个主节点2个从节点的MySQL集群
#configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: mysql
namespace: prod
data:
master.cnf: |
# 主节点MySQL的配置文件
[mysqld]
log-bin
slave.cnf: |
# 从节点MySQL的配置文件
[mysqld]
log-bin
read_only=1
replicate_ignore_db=information_schema
replicate_ignore_db=performance_schema
replicate_ignore_db=mysql
replicate_ignore_db=sys
init.sh: |
#!/bin/bash
until mysql -p"$MYSQL_ROOT_PASSWORD" -e "select 1;"; do sleep 1; done
[[ $HOSTNAME =~ -([0-9]+) ]] || exit 1
ordinal=${BASH_REMATCH[1]}
if [[ $ordinal -eq 0 ]]; then
mysql -p"$MYSQL_ROOT_PASSWORD" -e "grant replication slave on *.* to '$REPLIC_USER'@'%' identified by '$REPLIC_PASSWORD'"
mysql -p"$MYSQL_ROOT_PASSWORD" -e "FLUSH PRIVILEGES"
else
mysql -p"$MYSQL_ROOT_PASSWORD" -e "change master to master_host='mysql-0.mysql-svc',master_user='$REPLIC_USER',master_password='$REPLIC_PASSWORD';"
mysql -p"$MYSQL_ROOT_PASSWORD" -e "start slave"
fi
#sercet.yaml
apiVersion: v1
kind: Secret
metadata:
name: mysql
namespace: prod
type: Opaque
data:
pass: NlFBMFpGSTRUYzZ6UmU5VWc4amI= #6QA0ZFI4Tc6zRe9Ug8jb
rep_pass: bWtzdFE2M3ZuYmFQeUJ5eGR6Z3Y= #mkstQ63vnbaPyByxdzgv
rep_user: cmVw #rep
#mysql.yaml
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql
namespace: prod
spec:
selector:
matchLabels:
app: mysql
app.kubernetes.io/name: mysql
replicas: 3
serviceName: mysql-svc
template:
metadata:
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
initContainers:
- name: init-mysql
image: mysql:5.7.34
command:
- bash
- "-c"
- |
set -ex
# Generate mysql server-id from pod ordinal index.
[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1
ordinal=${BASH_REMATCH[1]}
echo [mysqld] > /mnt/conf.d/server-id.cnf
# Add an offset to avoid reserved server-id=0 value.
echo server-id=$((100 + $ordinal)) >> /mnt/conf.d/server-id.cnf
# cp config file to /mnt/conf.d
if [[ $ordinal -eq 0 ]]; then
cp /mnt/config-map/master.cnf /mnt/conf.d/
else
cp /mnt/config-map/slave.cnf /mnt/conf.d
fi
cp /mnt/config-map/init.sh /mnt/conf.d
volumeMounts:
- name: conf
mountPath: /mnt/conf.d/
- name: config-map
mountPath: /mnt/config-map/
containers:
- name: mysql
image: mysql:5.7.34
volumeMounts:
- name: conf
mountPath: /etc/mysql/conf.d
- name: data
mountPath: /var/lib/mysql/
env:
- name: MYSQL_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mysql
key: pass
- name: REPLIC_USER
valueFrom:
secretKeyRef:
name: mysql
key: rep_user
- name: REPLIC_PASSWORD
valueFrom:
secretKeyRef:
name: mysql
key: rep_pass
ports:
- name: mysql
containerPort: 3306
resources:
requests:
cpu: "500m"
memory: "500Mi"
limits:
cpu: "500m"
memory: "500Mi"
lifecycle:
postStart:
exec:
command: ["bash","/etc/mysql/conf.d/init.sh"]
volumes:
- name: config-map
configMap:
name: mysql
- name: conf
emptyDir: {}
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs" #这里使用的就是上面声名的Dynamic Volume Provisioning
resources:
requests:
storage: 2Gi
#service.yaml
apiVersion: v1
kind: Service
metadata:
name: mysql-svc
namespace: prod
labels:
app: mysql
app.kubernetes.io/name: mysql
spec:
ports:
- name: mysql
port: 3306
clusterIP: None #使用clusterIP: None 这样每个pod都会有一个独立的dns域名可以单独访问到,同时访问主节点就变成mysql-0.mysql-svc
selector:
app: mysql
---
apiVersion: v1
kind: Service
metadata:
name: mysql-read
namespace: prod
labels:
app: mysql
app.kubernetes.io/name: mysql
readonly: "true"
spec:
ports:
- name: mysql
port: 3306
selector:
app: mysql这里有几点需要注意一下:
这里创建集群使用的是
StatefulSet因为mysql集群之间存在拓步结构(必须先启动master节点再启动slaver节点),为了处理这种状态的关系所以使用了StatefulSet[[ $HOSTNAME =~ -([0-9]+)$ ]] || exit 1 ordinal=${BASH_REMATCH[1]}这段shell的意思是获取hostname中的数字,然后赋值个ordinal,这样通过判断ordinal就可以知道当前环境是主节点还是从节点。
StatefulSet创建的pod名称是有顺序的,pod-index,index会从0开始,这里规定pod-0为主节点mysql.yaml中的
serviceName必须跟Service里面的metadata.name一致,不然dns只能解析StatefulSetName-ServiceName到任意一个pod上,不能通过podsName-serviceName解析到指定的pod上面 StatefulSet | KubernetesserviceName (string), 必需
serviceName 是管理此 StatefulSet 服务的名称。 该服务必须在 StatefulSet 之前即已存在,并负责该集合的网络标识。 Pod 会获得符合以下模式的 DNS/主机名: pod-specific-string.serviceName.default.svc.cluster.local。 其中 “pod-specific-string” 由 StatefulSet 控制器管理。
因为我这里是用了一个自定义的
namespace,如果在本namespace上面通过podsName-serviceName是可以直接访问的,但是如果是其他namespace访问就要使用podsName-serviceName.my-namcespace才可以访问 详细我这里的
resources.requests和resources.limits的配置是一样的,这个属于是Qos中的GuaranteedQos中的类型:
Guaranteed(保障型):
- 条件: Pod 中所有容器的
resources.requests和resources.limits都相等,并且都设置了非零值。 - 特点:
- 优先级最高,资源得到最强的保障。
- 当节点资源不足时,Guaranteed Pod 不会被驱逐,除非是系统保留资源不足。
- 适用场景: 对资源要求高且稳定的应用,例如数据库、核心服务等。
Burstable(可突增型):
- 条件: Pod 中至少有一个容器的
resources.requests设置了值,并且resources.requests小于resources.limits。 - 特点:
- 优先级中等,可以在
resources.requests的基础上使用更多资源,但不能超过resources.limits。 - 当节点资源不足时,Burstable Pod 可能被驱逐,优先级低于 Guaranteed Pod。
- 优先级中等,可以在
- 适用场景: 对资源需求有波动,但峰值使用不会太高的应用,例如 Web 服务器、API 服务等。
BestEffort(尽力而为型):
- 条件: Pod 中所有容器都没有设置
resources.requests和resources.limits。 - 特点:
- 优先级最低,只能使用节点上剩余的资源。
- 当节点资源不足时,BestEffort Pod 会被优先驱逐。
- 适用场景: 对资源要求不高,可以容忍被驱逐的应用,例如批处理任务、测试任务等。
- 条件: Pod 中所有容器的
redis集群
redis高可用服务一般有三种类型:
Redis replication redis的主从复制 Redis replication | Docs
Redis Sentinel 在redis的主从复制基础上添加了哨兵,确保在redis-master下线了以后,重新从redis-slaver中选举一个新的master出来,保证服务可用,当旧的redis-master上线后就变成redis-slaver。High availability with Redis Sentinel | Docs
Redis Cluster 这个是由多个redis主从一起组成的集群,数据会被分散到每个redis主从上面 Scale with Redis Cluster | Docs
会有16384 hash slots 在 Redis Cluster,它们会被分散到不同的节点上面,读写对应的数据将会在对应的节点中进行
with Redis Cluster, you get the ability to:
- Automatically split your dataset among multiple nodes.
- Continue operations when a subset of the nodes are experiencing failures or are unable to communicate with the rest of the cluster.
而这次部署的就是3个node的Redis Cluster其中每个node由一个主一个从组成,所以一共有6个redis服务
#configmap
apiVersion: v1
kind: ConfigMap
metadata:
name: redis
namespace: prod
data:
redis.conf: |
port 6379
cluster-enabled yes #开启集群模式
cluster-node-timeout 5000
cluster-config-file /data/nodes.conf
appendonly yes
#sercet
apiVersion: v1
kind: Secret
metadata:
name: redis
namespace: prod
type: Opaque
data:
pass: ZHFYbkdJNEUxM28zY0d6V3E1QXI= #dqXnGI4E13o3cGzWq5Ar
#redis
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis
namespace: prod
spec:
selector:
matchLabels:
app: redis
app.kubernetes.io/name: redis
serviceName: redis-svc
replicas: 6
template:
metadata:
labels:
app: redis
app.kubernetes.io/name: redis
spec:
initContainers:
- name: init-redis
image: redis:7.4
env:
- name: REDISCLI_AUTH
valueFrom:
secretKeyRef:
name: redis
key: pass
command:
- bash
- "-c"
- |
set -ex
cp /mnt/config-map/redis.conf /mnt/conf.d
echo "requirepass $REDISCLI_AUTH" >> /mnt/conf.d/redis.conf
echo "masterauth $REDISCLI_AUTH" >> /mnt/conf.d/redis.conf
volumeMounts:
- name: conf
mountPath: /mnt/conf.d/
- name: config-map
mountPath: /mnt/config-map/
containers:
- name: redis
image: redis:7.4
command: ["redis-server"]
args:
- /usr/local/etc/redis/redis.conf
- --cluster-announce-ip
- "$(MY_POD_IP)"
volumeMounts:
- name: conf
mountPath: /usr/local/etc/redis/
- name: data
mountPath: /data/
env:
- name: REDISCLI_AUTH
valueFrom:
secretKeyRef:
name: redis
key: pass
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
ports:
- name: redis
containerPort: 6379
resources:
requests:
cpu: "100m"
memory: "200Mi"
limits:
cpu: "100m"
memory: "200Mi"
volumes:
- name: config-map
configMap:
name: redis
- name: conf
emptyDir: {}
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "nfs"
resources:
requests:
storage: 2Gi
#service
apiVersion: v1
kind: Service
metadata:
name: redis-svc
namespace: prod
labels:
app: redis
app.kubernetes.io/name: redis
spec:
ports:
- name: redis
port: 6379
clusterIP: None #这里跟上面的mysql一样,通过redis-index.redis-svc来访问不同的redis节点
selector:
app: redis
#job
apiVersion: batch/v1
kind: Job
metadata:
name: redis-cluster-create
namespace: prod
spec:
template:
spec:
containers:
- name: redis-cli
image: redis:7.4
env:
- name: REDISCLI_AUTH
valueFrom:
secretKeyRef:
name: redis
key: pass
command: ["/bin/sh", "-c"]
args:
- |
redis-cli --cluster create \
redis-0.redis-svc:6379 \
redis-1.redis-svc:6379 \
redis-2.redis-svc:6379 \
redis-3.redis-svc:6379 \
redis-4.redis-svc:6379 \
redis-5.redis-svc:6379 \
--cluster-replicas 1 -a $REDISCLI_AUTH --cluster-yes #cluster-replicas 1 表示为每一个主节点分配一个从节点,这样每个node就有两个redis组成一个主一个从,这样3由个node组成的redis cluster就要6个redis
restartPolicy: Never
backoffLimit: 1这里要注意几点
redis部署完了还要执行创建集群的命令,这里利用了job来完成这个
密码配置说明
- requirepass表示redis的密码
- masterauth 表示redis主从时候的密码 两者都要同时设置,不然会存在因密码错误无法同步数据
- 如果想更加细致化的控制redis的权限可以新建用户并且使用
ACL的功能 ACL | Docs (redis.io)
pod的ip问题,在第一次启动redis集群的时候,会把集群信息写入
/data/nodes.conf类似127.0.0.1:6379> CLUSTER NODES
171465406d506a29e3bfcd2cf62a578dfe048613 10.42.0.109:6379@16379 master - 0 1723877446841 3 connected 10923-16383
6ddad196c4998856d7587a2a31012bd3570342e8 10.42.0.111:6379@16379 myself,slave 50fc764dae51be95e3f24527b2458ceb44533a84 0 0 2 connected
e43744bd3bd58f04158ea90bc044b1b200e0b153 10.42.1.40:6379@16379 slave 171465406d506a29e3bfcd2cf62a578dfe048613 0 1723877446842 3 connected
2ca5a824b3edca3baaf8caacf6d036061c9cb647 10.42.0.110:6379@16379 slave 5947054d518ac8ed6b1aeb4b378ad50eedd3bcbb 0 1723877445837 1 connected
5947054d518ac8ed6b1aeb4b378ad50eedd3bcbb 10.42.0.108:6379@16379 master - 0 1723877445000 1 connected 0-5460
50fc764dae51be95e3f24527b2458ceb44533a84 10.42.1.39:6379@16379 master - 0 1723877446000 2 connected 5461-10922但是在重启redis集群后pod的ip会更改,导致集群状态为
failed。解决可以参考
Gin后端
代码 k8s_demo/web/back at main · kehaha-5/k8s_demo (github.com)
这个gin后端的话,除了提供api服务以外它还而外监听一个端口用来给pod提供健康检测 配置存活、就绪和启动探针
FROM alpine:3.20.2
COPY ./k8s_demo /app/k8s_demo
COPY ./config-prod.yaml /app/config-prod.yaml
RUN set -eux && sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/g' /etc/apk/repositories
RUN apk update && apk add tzdata我们要把后端代码和所需要的环境打包成镜像,因为我的k3s使用的运行时是containerd,所以这里利用docker进行打包,然后导出镜像再导入到containerd里面
docker build -t k8s_demo/back:1.0 . #注意-t的格式,只有这样的格式导入到ctr中才会保留
docker save k8s_demo/back -o k8s_demo_back.tar
ctr -n k8s.io images import k8s_demo_back.tar #导入时,要选择k8s.io的namesapce 不然可能出现pod找不到image#k8s-demo-back-end
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8s-demo-back-end
namespace: prod
labels:
app: k8s-demo-back-end
spec:
replicas: 2
selector:
matchLabels:
app: k8s-demo-back-end
template:
metadata:
labels:
app: k8s-demo-back-end
spec:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- k8s-demo-back-end
topologyKey: kubernetes.io/hostname
containers:
- name: k8s-demo-back-end
image: docker.io/k8s_demo/back:1.0@sha256:bf9041895c649d1a586851e2f2e072fb9680fe134c359ea59a577b010029ba5d
command: ["/app/k8s_demo"]
args: ["-c","/app/config-prod.yaml"]
ports:
- name: api-port
containerPort: 40814
livenessProbe:
httpGet:
path: /api/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 3
env:
- name: REDIS_PASSWORD
valueFrom:
secretKeyRef:
name: redis
key: pass
- name: MYSQL_PASSWORD
valueFrom:
secretKeyRef:
name: mysql
key: pass
- name: GIN_MODE
value: "release"
resources:
requests:
cpu: "200m"
memory: "200Mi"
limits:
cpu: "1000m"
memory: "500Mi"
#service.yaml
apiVersion: v1
kind: Service
metadata:
name: k8s-demo-back-end-service
namespace: prod
labels:
name: k8s-demo-back-end-service
spec:
selector:
app: k8s-demo-back-end
ports:
- protocol: TCP
name: api-port
port: 40814
targetPort: 40814
clusterIP: None这里要注意一下,因为我一个共有3台服务器,除去一台专门的前端服务器,那我还有两台服务器,所以这里的replicas设置为2,然后我想让每个pod尽量不要调度到同一个节点上面,所以使用了affinity.podAntiAffinity尽量不要调度到已经有app=k8s-demo-back-end的节点上面
root@node-m:~/k8s# kubectl get pods -n prod -l app=k8s-demo-back-end -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k8s-demo-back-end... 1/1 Running 0 28s 10.42.1.42 node-s <none> <none>
k8s-demo-back-end... 1/1 Running 0 27s 10.42.0.116 node-m <none> <none>前端部署
代码 k8s_demo/web/front/k8s_demo at main · kehaha-5/k8s_demo (github.com)
这里也是要使用docker进行打包
FROM alpine:3.20.2
COPY ./dist/ /app/导入到containerd
docker build -t k8s_demo/front:1.0 .
docker save k8s_demo/front -o k8s_demo_front.tar
ctr -n k8s.io images import k8s_demo_front.tar#configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: web-nginx
namespace: prod
data:
app.conf: |
server {
listen 80;
listen [::]:80;
server_name localhost;
#access_log /var/log/nginx/host.access.log main;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
try_files $uri $uri/ /index.html; #vue3的history模式下的路由配置
}
}
#k8s-demo-back-front
apiVersion: apps/v1
kind: Deployment
metadata:
name: k8s-demo-back-front
namespace: prod
spec:
selector:
matchLabels:
app: k8s-demo-back-front
app.kubernetes.io/name: k8s-demo-back-front
template:
metadata:
labels:
app: k8s-demo-back-front
app.kubernetes.io/name: k8s-demo-back-front
spec:
tolerations:
- key: "type"
operator: "Equal"
value: "res"
effect: "NoSchedule"
initContainers:
- name: init-nginx
image: docker.io/k8s_demo/front:1.0@sha256:fecfc2dc67c49d8ff27a77cff8aee431f9baaee3ffc0fd22da8e8da20caaeddf
command:
- sh
- "-c"
- |
set -ex
cp -r /app/* /mnt/app/
volumeMounts:
- name: app
mountPath: /mnt/app/
containers:
- name: app-nginx
image: nginx:1.27.1-alpine3.20
volumeMounts:
- name: app
mountPath: /usr/share/nginx/html/
- name: config-map
mountPath: /etc/nginx/conf.d/
ports:
- name: app-nginx
containerPort: 80
volumes:
- name: app
emptyDir: {}
- name: config-map
configMap:
name: web-nginx
#service.yaml
apiVersion: v1
kind: Service
metadata:
name: k8s-demo-back-front-service
namespace: prod
labels:
name: k8s-demo-back-front-service
spec:
selector:
app: k8s-demo-back-front
ports:
- protocol: TCP
name: web
port: 80
targetPort: 80
clusterIP: None
这里需要注意一下我使用了tolerations容忍,容忍了节点可以存在type=res的键值对,刚好对应了node-res这个专门用来运行前端的节点
root@node-m:~/k8s# kubectl get pods -n prod -l app=k8s-demo-back-front -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
k8s-demo-back-front... 1/1 Running 3 (3h10m ago) 23h 10.42.2.41 node-res <none> <none>ingress
现在所有的服务都部署了,但是需要把它们统一暴露出去给外部访问,这里就用到了ingress,ingress可以说是管理service的service所以就是它来暴露服务到外部
为了让ingress可以正常工作,我们必须要有一个可用的ingress控制器 Ingress 控制器 | Kubernetes
这里使用的是k3s默认使用的是Traefik ingress controller的,所以第一步先要部署traefik的dashboard
Traefik dashboard
apiVersion: v1
kind: Namespace
metadata:
name: traefik-dashboard
labels:
name: traefik-dashboard
---
apiVersion: traefik.io/v1alpha1
kind: IngressRoute
metadata:
name: traefik-dashboard
namespace: traefik-dashboard
spec:
routes:
- match: Host(`traefik.localhost.com`) && (PathPrefix(`/api`) || PathPrefix(`/dashboard`))
kind: Rule
services:
- name: api@internal
kind: TraefikService
middlewares:
- name: auth
---
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: auth
namespace: traefik-dashboard
spec:
basicAuth:
secret: authsecret # Kubernetes secret named "secretName"
---
apiVersion: v1
kind: Secret
metadata:
name: authsecret
namespace: traefik-dashboard
data:
users:
cm9vdDokYXByMSRibUhSclNOaSQ0L2d4L0xNMmpzVGdBRTUzMTcwSEkuCgo= #htpasswd -nb root wwM9yCz52mWpWysVONM0 | base64这个就是部署Traefik dashboard的配置,它就是使用ingress route把服务暴露到了traefik.localhost.com的/dashboard和/api。同时我还使用了中间件来做用户认证,在访问的时候必须输入账号和密码才能正常访问,否则就是401。
除此之外,我还要修改本地的host文件把traefik.localhost.com这个域名指向我的节点ip。之后访问http://traefik.localhost.com/dashboard/#/即可
参考:
Traefik Dashboard Documentation - Traefik
Traefik BasicAuth Documentation - Traefik
服务配置
apiVersion: traefik.io/v1alpha1
kind: Middleware
metadata:
name: header
namespace: prod
spec:
headers:
accessControlAllowMethods:
- "GET"
- "OPTIONS"
- "POST"
- "PUT"
accessControlAllowHeaders:
- "*"
addVaryHeader: true
accessControlAllowOriginList:
- "*" #这里最好设置为前端的域名 web.k8s.demo
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web-ingress
namespace: prod
annotations:
traefik.ingress.kubernetes.io/router.middlewares: prod-header@kubernetescrd
spec:
rules:
- host: api.k8s.demo
http:
paths:
- path: /api
pathType: Prefix
backend:
service:
name: k8s-demo-back-end-service
port:
number: 40814
- host: web.k8s.demo
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: k8s-demo-back-front-service
port:
number: 80这个就是我的服务配置,这里使用了api.k8s.demo访问后端,web.k8s.demo访问前端,其中web.k8s.demo要把ip绑定到前端节点上面,同时这里还写了一个中间件来解决跨域问题。
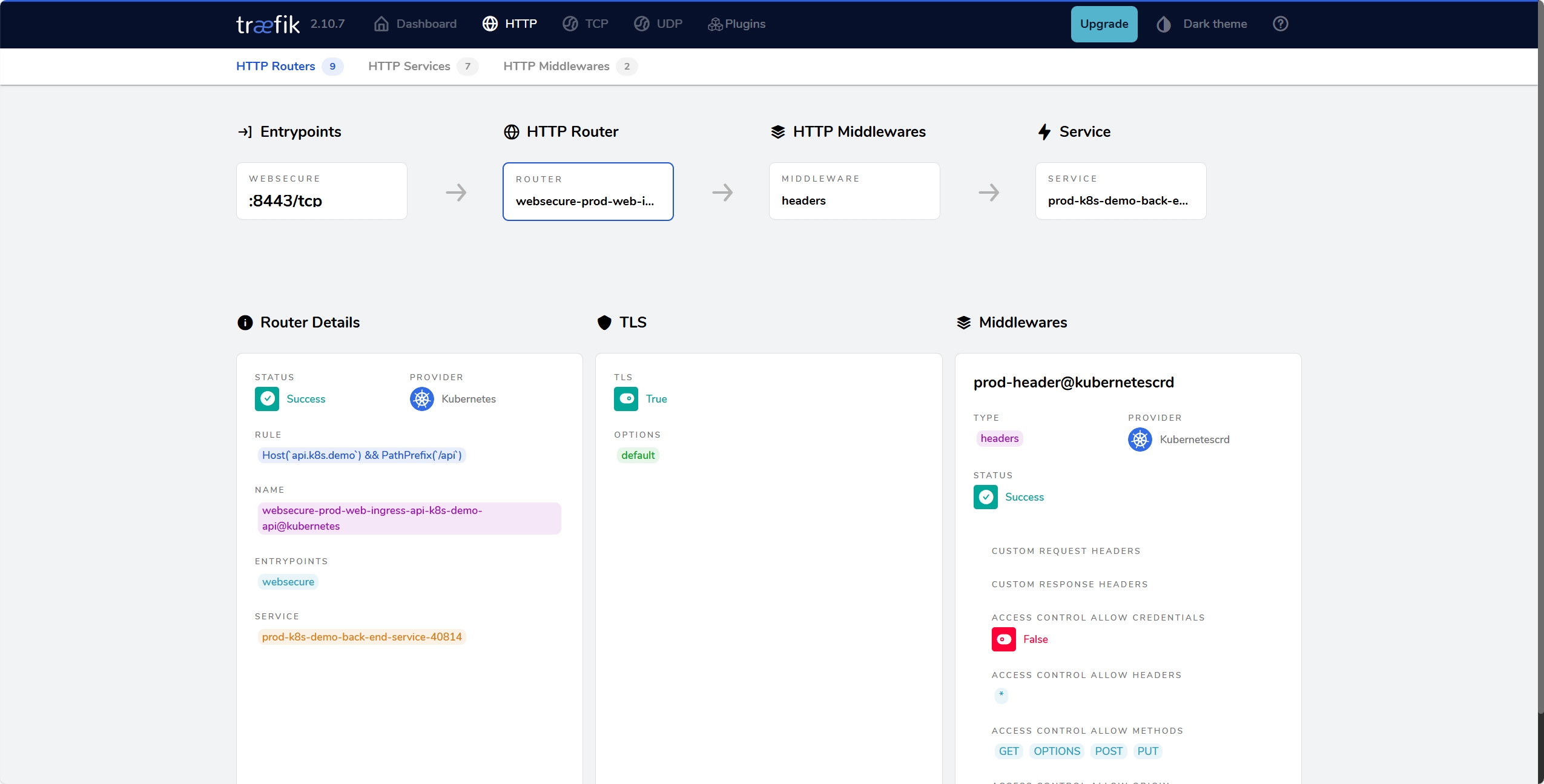
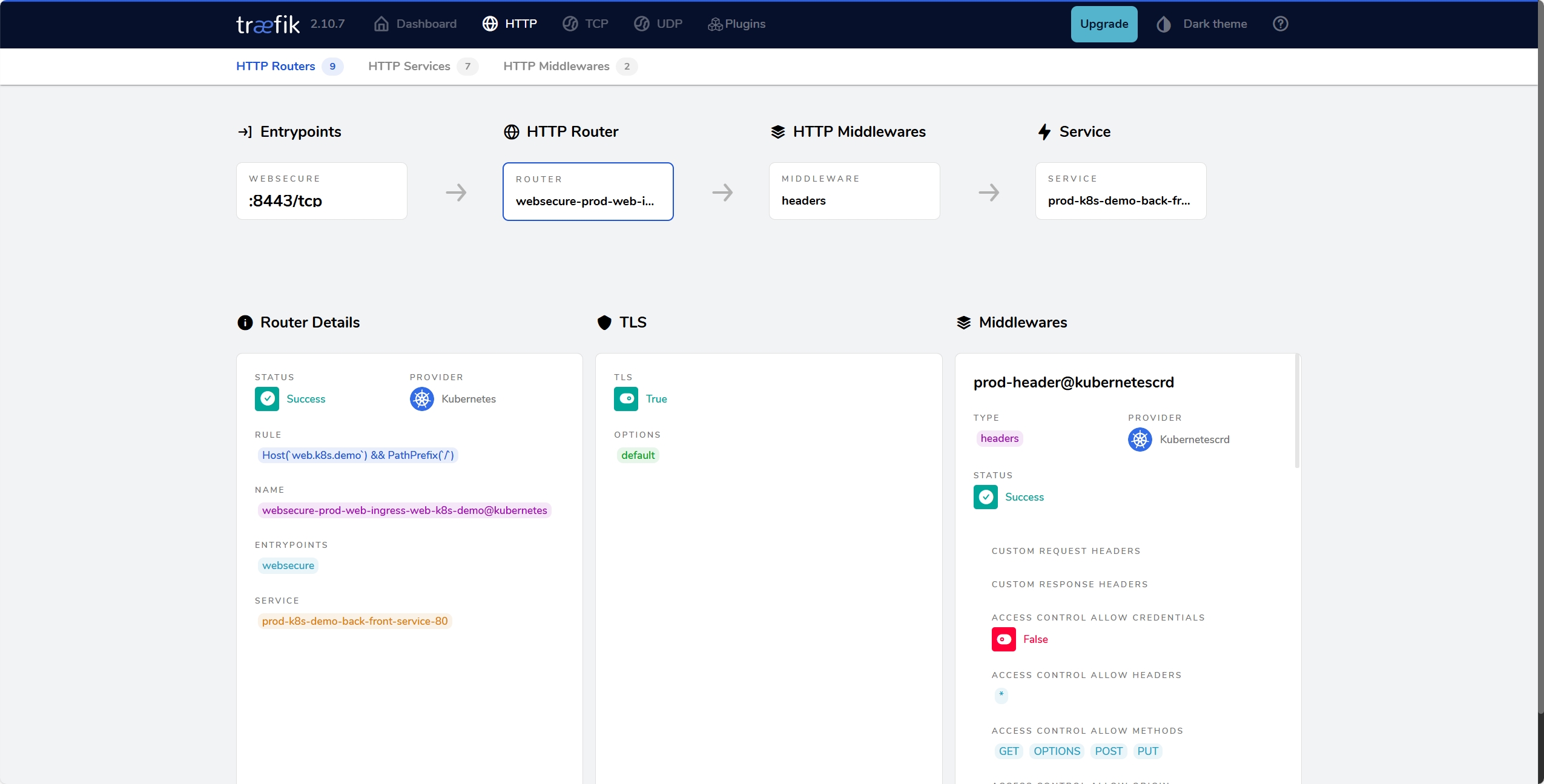
这里需要注意两点:
在
Ingress里面使用中间件需要遵循一定的命名规则apiVersion: traefik.io/v1alpha1 kind: Middleware metadata: name: stripprefix namespace: appspace spec: stripPrefix: prefixes: - /stripit --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress namespace: appspace annotations: # referencing a middleware from Kubernetes CRD provider: # <middleware-namespace>-<middleware-name>@kubernetescrd "traefik.ingress.kubernetes.io/router.middlewares": appspace-stripprefix@kubernetescrd spec: # ... regular ingress definition在后面实现的时候发现因为使用了ingress 导致无论是访问前端还是后端流量都会走到节点上面,所以如果真的要把流量分开,最好是不用
ingress,使用service中的NodePort公开服务
ok 以上就是从零到一--搭建web项目集群所有内容了