最近写了一个c++项目来学习,在完成后,我想利用
valgrind对服务端和客户端进行性能分析
前言
客户端和服务端都在本地运行
在未开始优化时,客户端下载速度

速度只有13MB
工具
本次性能分析利用的是valgrind的callgrind工具
# 分析命令
valgrind --tool=callgrind --callgrind-out-file=./valgrindCheck/callgrind/client --separate-threads=yes ./build/TRANFILER_CLIENT #客户端
valgrind --tool=callgrind --callgrind-out-file=./valgrindCheck/callgrind/server --separate-threads=yes ./build/TRANFILER_SERVER #服务端
#--separate-threads=<no|yes> [default: no]
# This option specifies whether profile data should be generated separately for every thread. If yes, the file names get "-threadID" appended.结果分析用的是 kcachegrind
测试过程
客户端和服务端分别执行以上命令,然后客户端下载一个文件(大约200M)查看结果(客户端和服务端打包的都是release版本)
分析
客户端
因为是要对下载性能进行检测,因此我挑了下载代码来进行分析
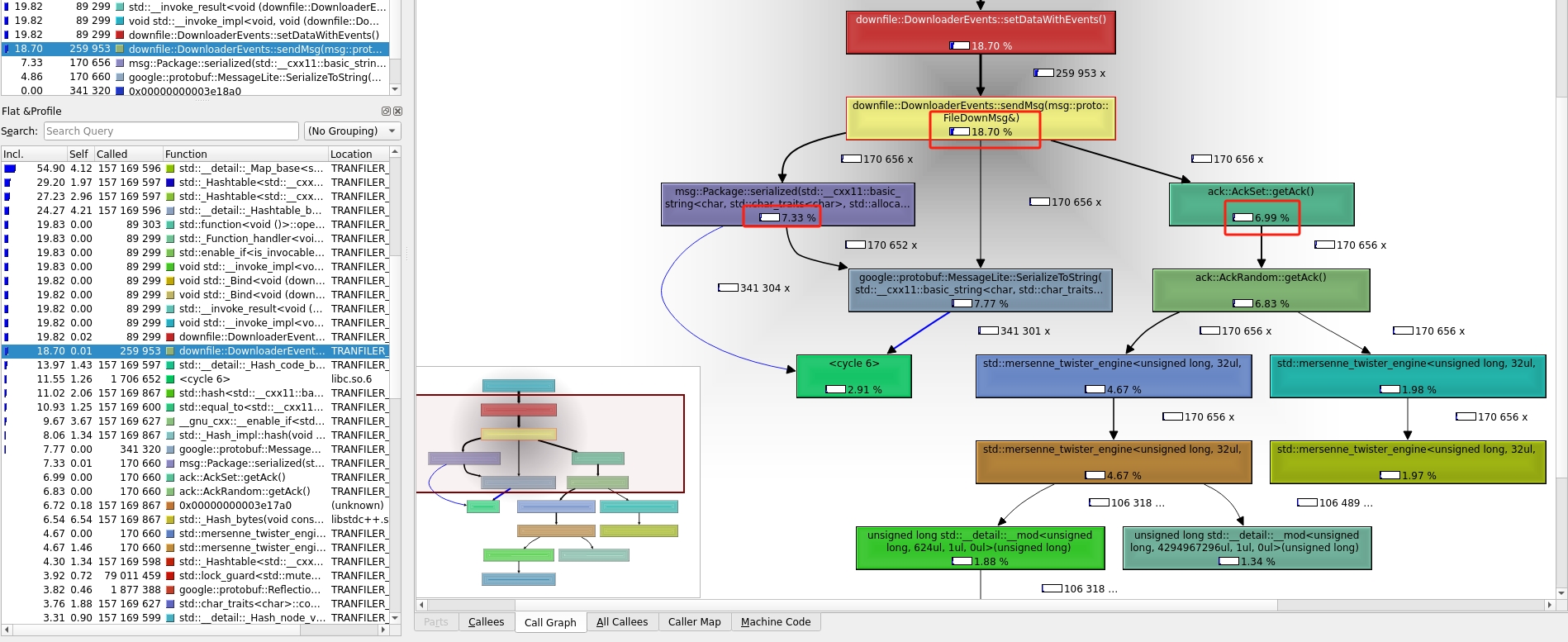
上图是客户端的发送消息的代码,从图中可以分析出来 google::protobuf 使用了一半的cpu,另一半是被 setAck()使用了
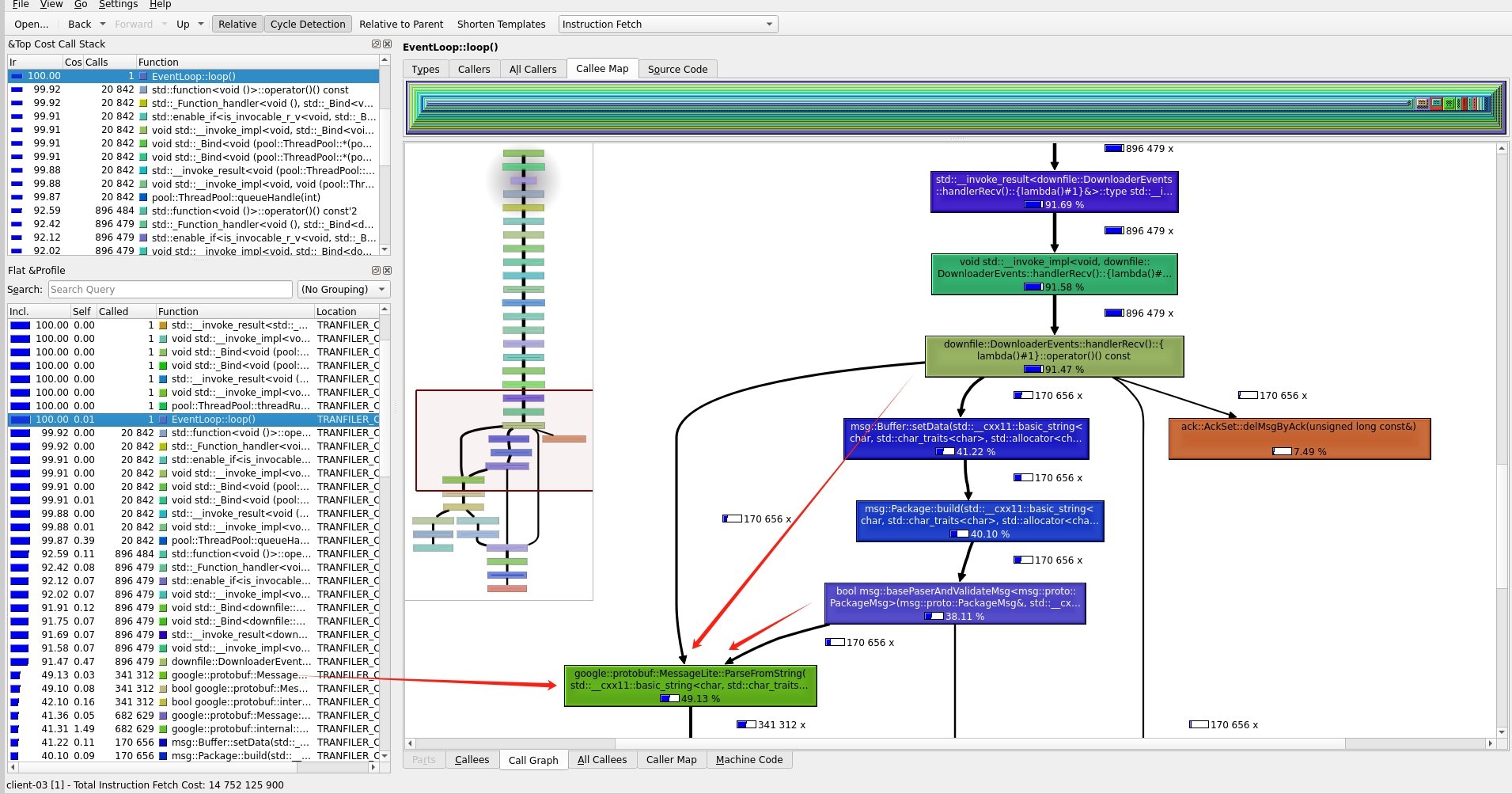
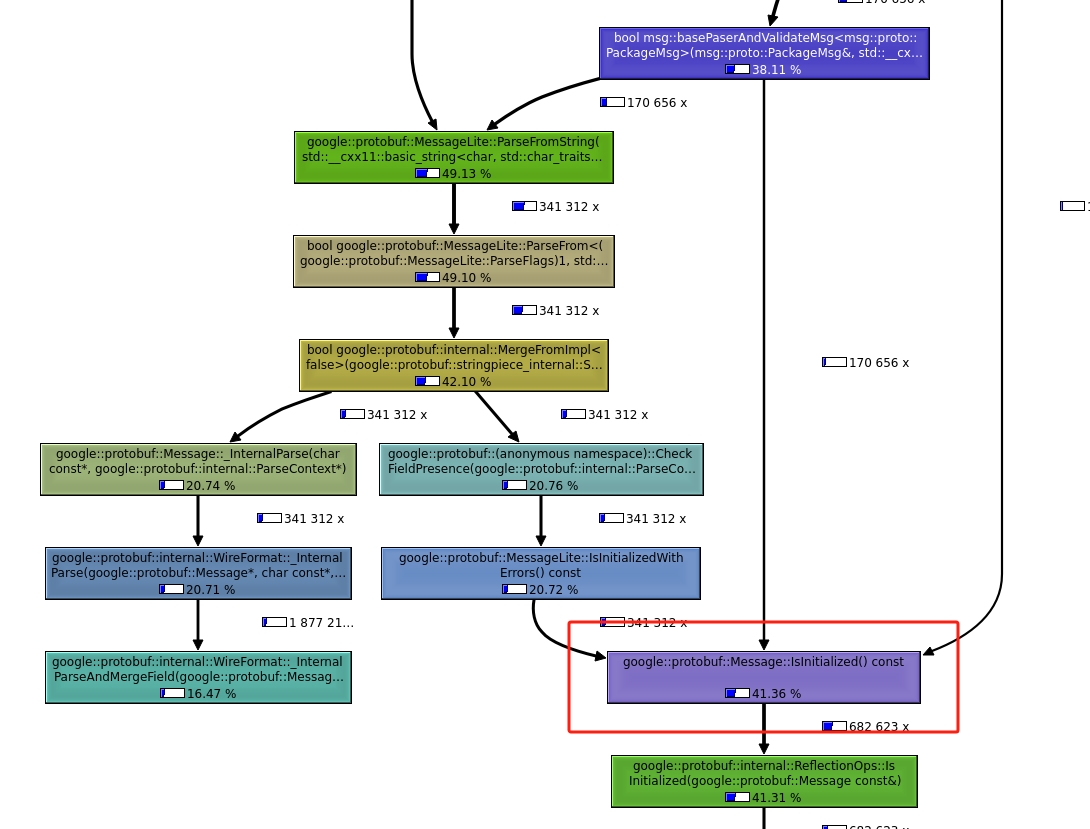
上面两张图都是客户端的接收数据的代码,从图中可以分析出来 google::protobuf 使用了快80%的cpu
服务端
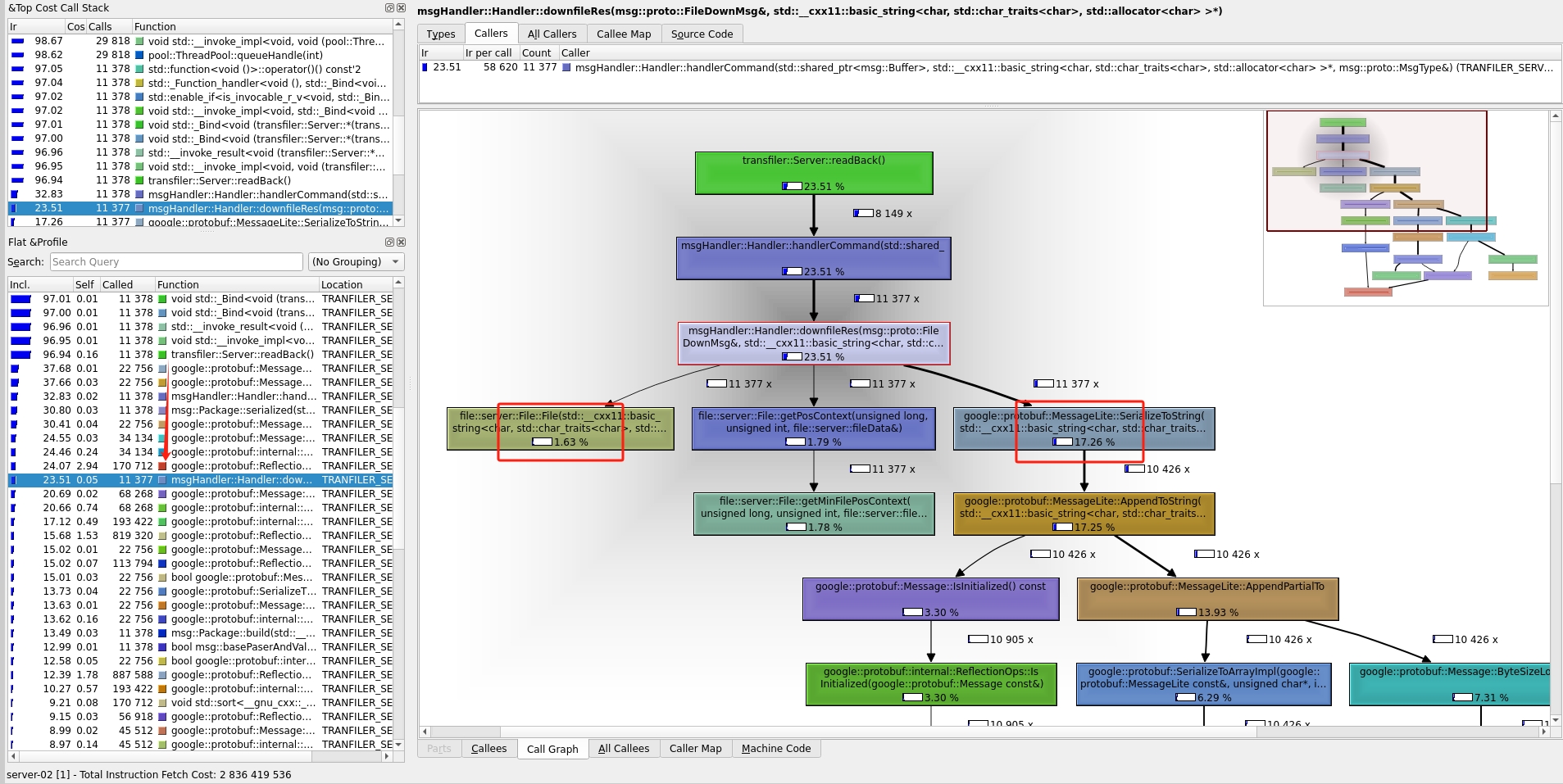
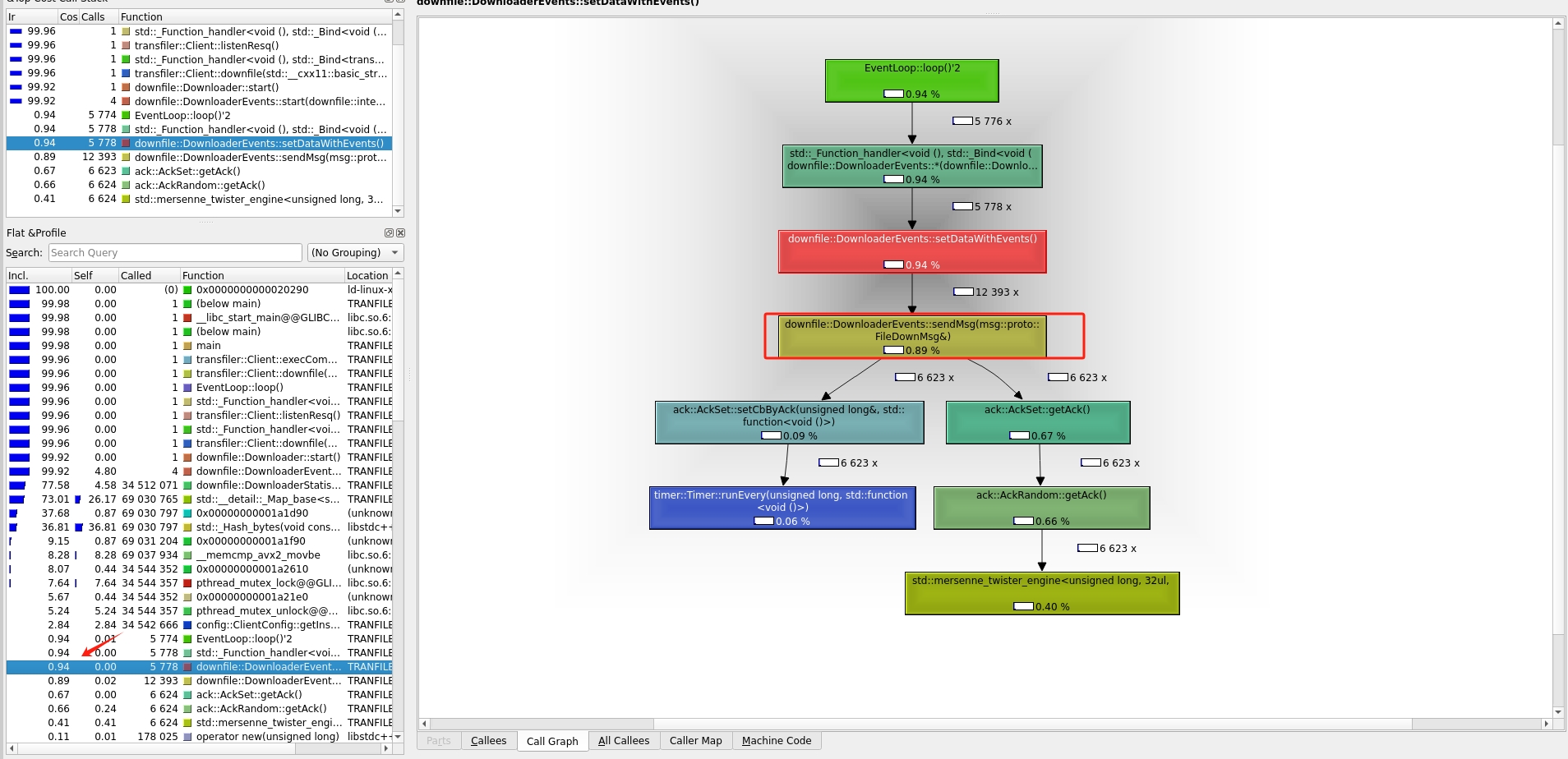
从图中可以看出,服务端中获取文件内容 file::server 使用了1.63%的cpu,而处理google::protobuf使用了 17.26%
结论
因此得出导致性能问题的原因大概率是google::protobuf,打开proto文件
syntax = "proto2";
package msg.proto;
option optimize_for = CODE_SIZE;
message FileDownMsg{
required string hash = 1;
required uint64 startPos =2;
required uint64 dataIndex = 3;
optional int64 size = 4;
optional bytes data = 5;
}发现了问题:optimize_for用的是CODE_SIZE 为什么当初会用这个,我也不知道🤡,只要把optimize_for删除了默认使用的就是SPEED 文档
再次测试

速度达到23MB,提高了75% 🤞
客户端
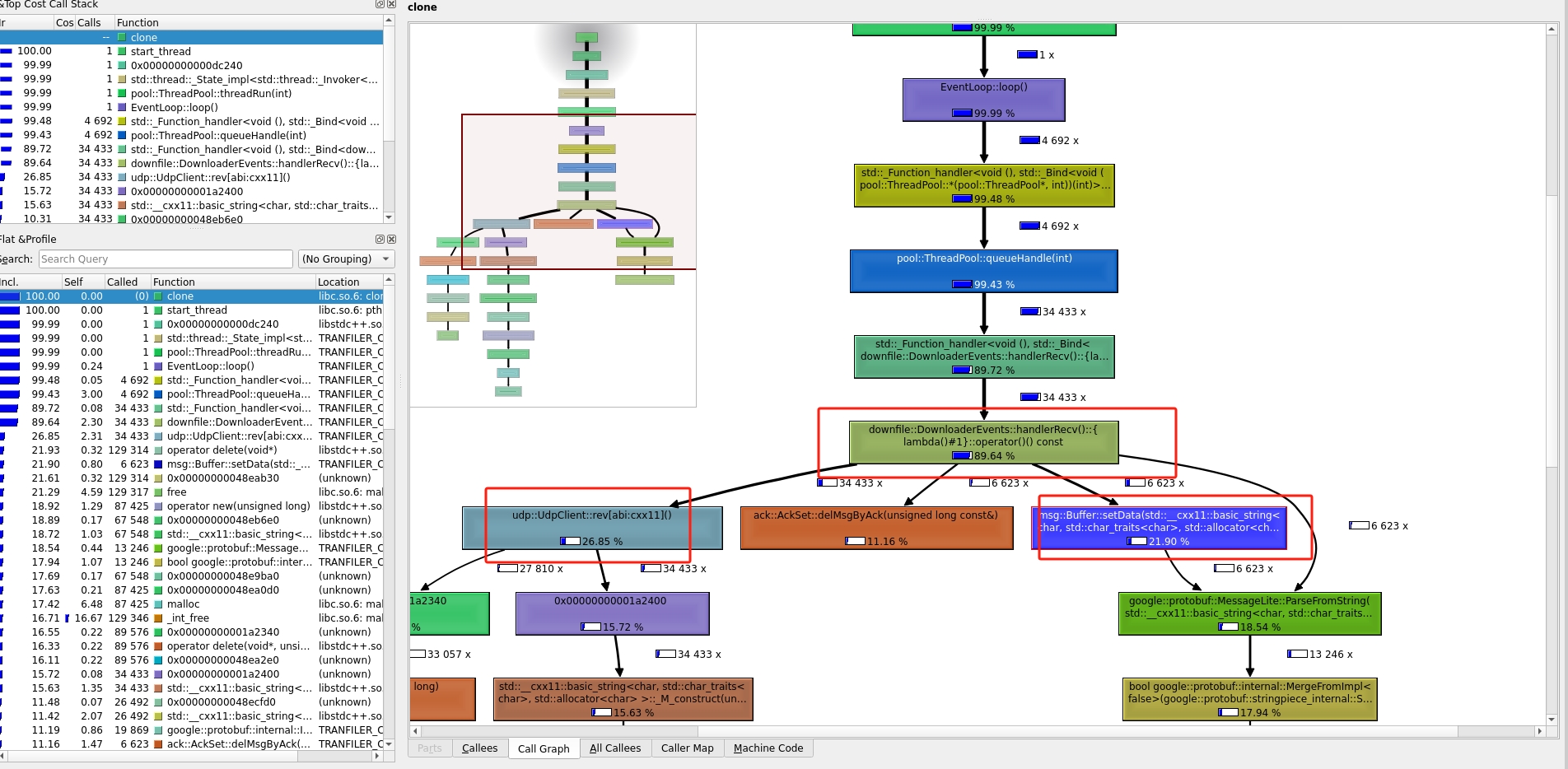
由上面两幅图可以知道,经过优化后,接收数据中的 google::protobuf 的性能使用跟 recvfrom 的使用几乎一样了,发送端更是看不到了google::protobuf性能统计
服务端
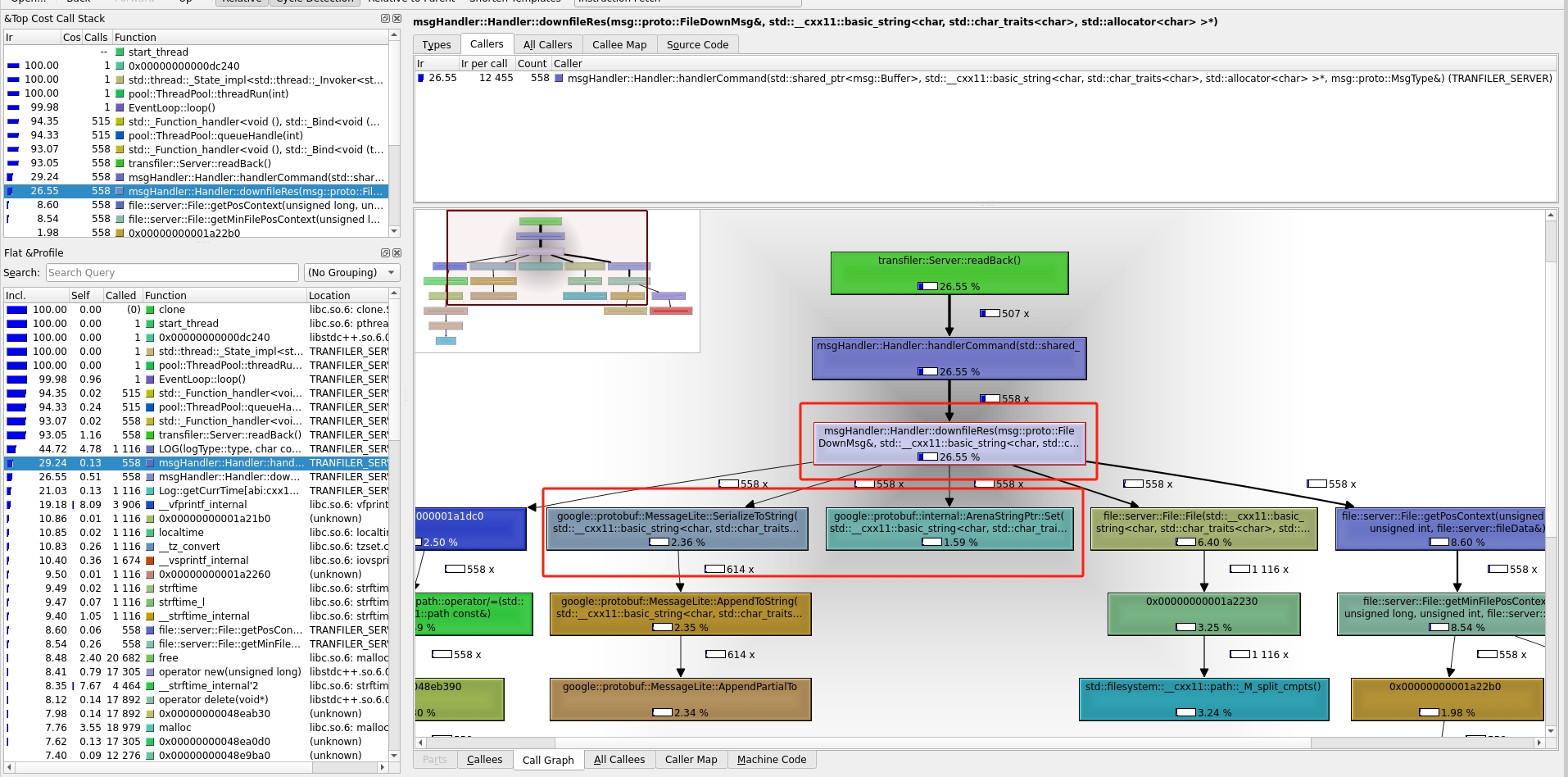
由上图也知服务端的google::protobuf 的性能使用也明显下降了
还能再优化吗
第二次分析
但是,在服务端中的处理请求中为什么只使用了26%左右的cpu,那其他cpu性能去哪里捏 🤔
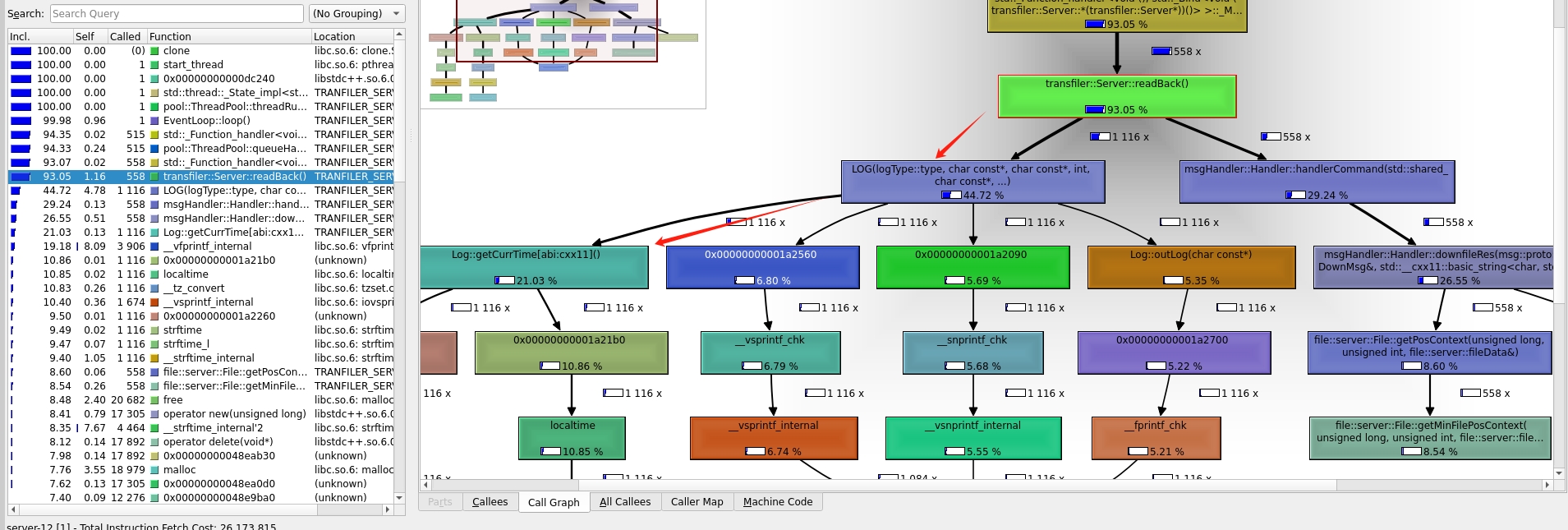
通过查看整个调用栈我发现了 log 函数使用了40%的cpu,尤其记录log时获取的时间函数
获取时间
获取时间的代码如下
std::string Log::getCurrTime() {
std::time_t t = std::time(NULL);
std::string mbstr(50, 0);
std::strftime(&mbstr[0], mbstr.size(), "%F-%T", std::localtime(&t));
return mbstr;
}那么这段代码里面有什么性能问题捏,可以在kcachegrind中点击log函数进行查看
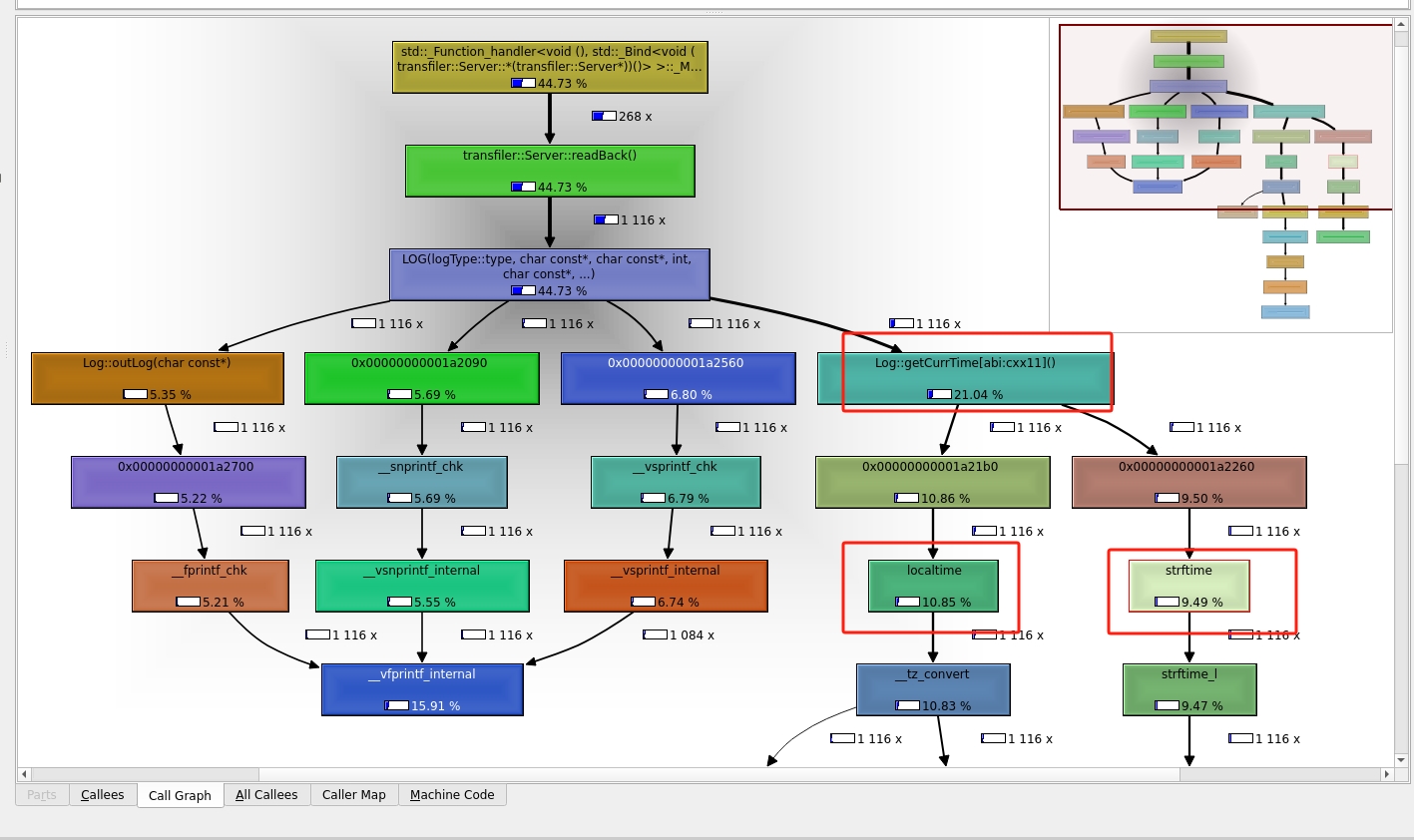
发现了就是 strftime 和 localtime,那为什么它们执行怎么慢捏,因为它们都进行了syscall(详情请看strftime,localtime)
那如何进行修改
第一种方法是:修改代码,代码参考这里
第二种方法是:只生产 timeval,在真正进行写入的时候在转换成日期(log线程)但是既然都进行了优化了,肯定是选择第二个方案,并且采用参考代码里面的func3(我都不显示正常请求的log了,详细请看后文)
再次测试 🤡

??? 为什么速度基本上跟上次一样,速速打开kcachegrind进行分析 🤺🤺🤺
第三次分分析
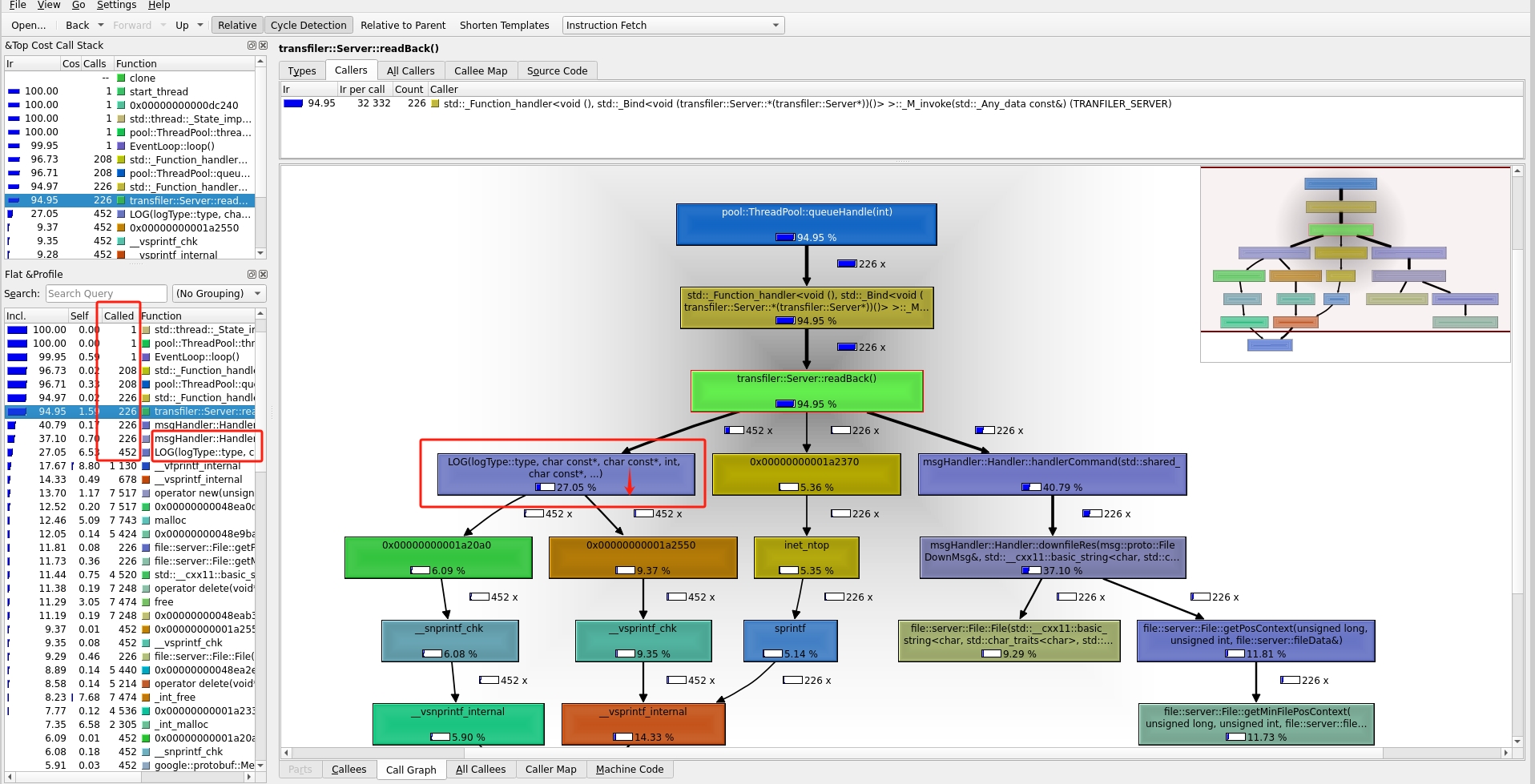
可以看到log的cpu占用确实变少了,但还是占用了27%的cpu,所以不如点进去仔细分析一下那行代码占用大量cpu
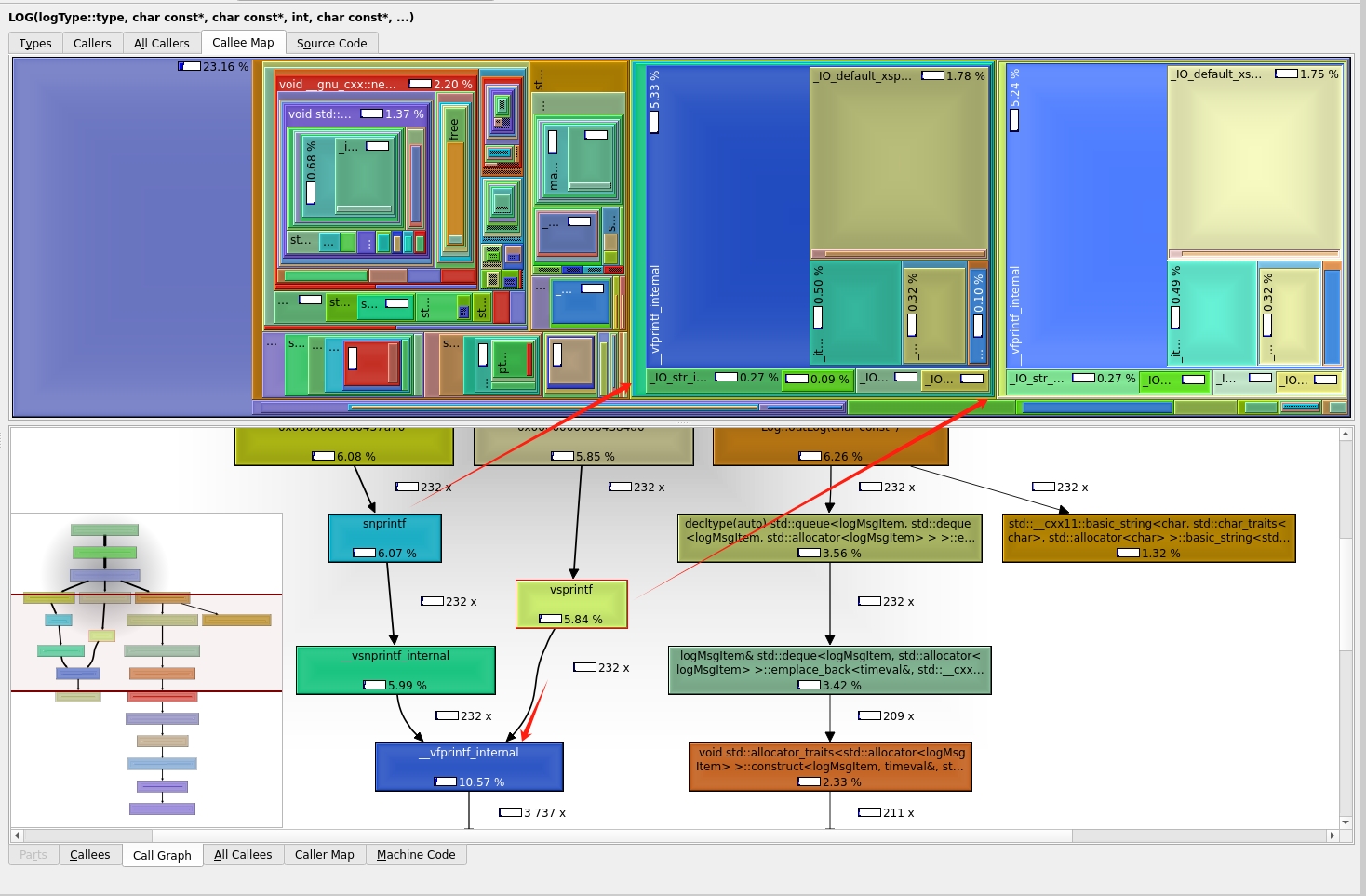
进入log后,可以看到在Callee Map中,最大的两块分别是 sprintf vsprintf
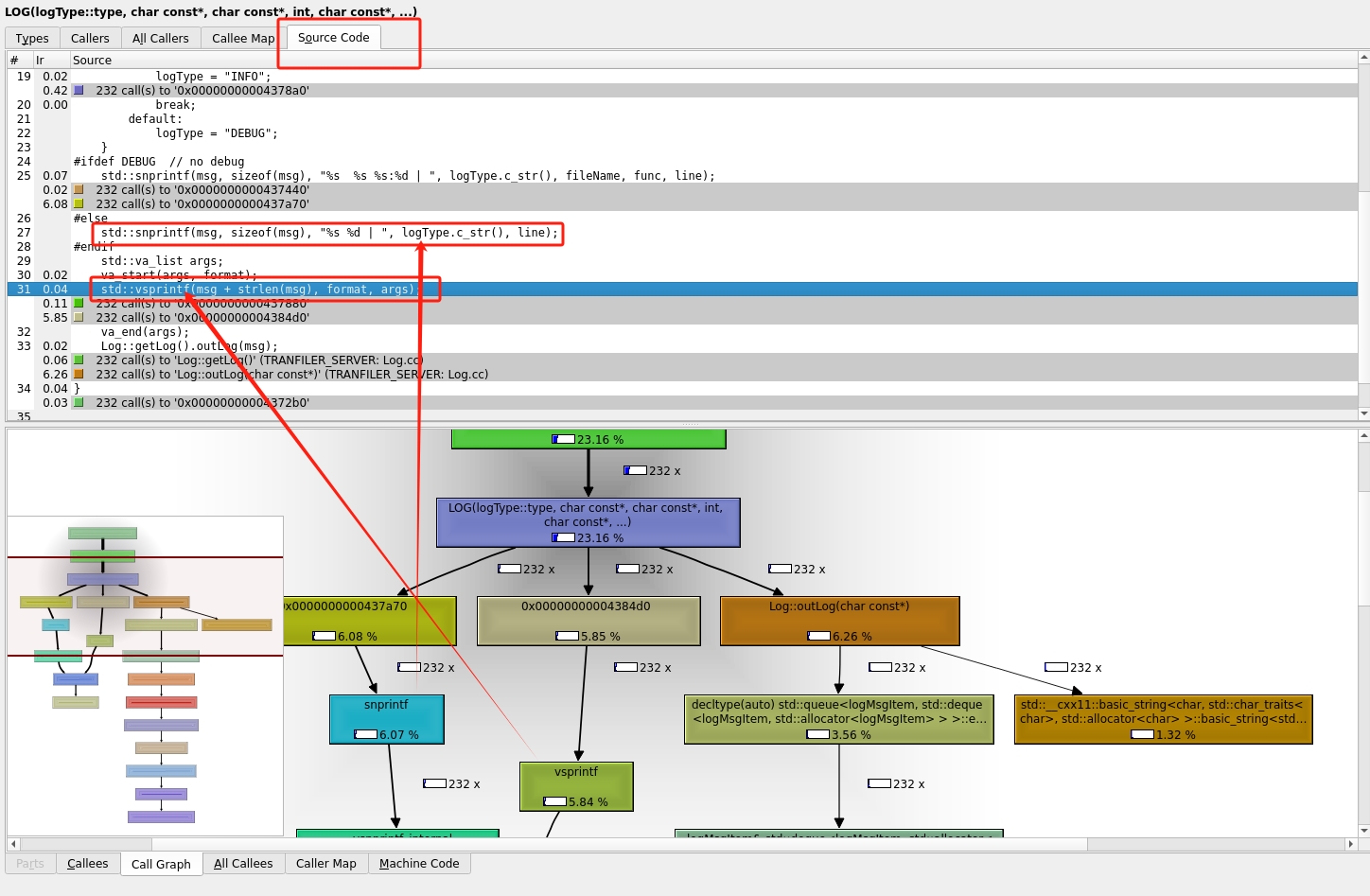
查看到对应的代码就是输出时的格式化(要在debug模式下才可以看到源码),那这个真的没有办法优化了吗,其实还是有的,就是关闭正常请求时的log显示。因为一个请求就会输出两个log信息
2024-03-xx 09:03:44.975857 INFO 63 | udp recvfrom data to ip 127.0.0.1 prot 35512 ack is 1315955221
2024-03-xx 09:03:44.975940 INFO 63 | udp recvfrom data to ip 127.0.0.1 prot 35512 ack is 508775843
2024-03-xx 09:03:44.975978 INFO 90 | udp send data to ip 127.0.0.1 prot 35512 ack is 3372925139
2024-03-xx 09:03:44.976044 INFO 90 | udp send data to ip 127.0.0.1 prot 35512 ack is 508775843而在下载文件的时候一秒钟会传输大量的数据包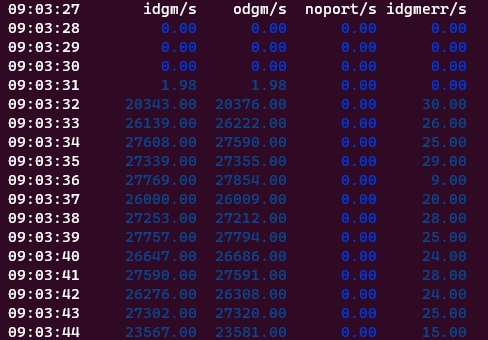
这就会大量调用log函数,从而影响性能。但是为了调试方便,可以把这个是否显示正常请求的log写入到配置文件中,根据实际进行配置
最终结果
经过了上述log模块的修改,以下就是最终结果,从刚开始的13M提升到35M 🤞🤞